以下为个人学习笔记整理
# python 源码阅读
# 数据类型分析
# PyIntObject——python 中的 int 类型
- python 计算两个整数 ()
- 出现溢出后会转换成 long 类型(无限大整数)。
- python 整数缓存
[-5~256]的整数。- 提供多个缓存块,每个能够存放
(100/8)数量的 int 类型。 - 控制这些块的结构是一个单向链表(指向每个块中第一个违背使用的内存块)。
- 申请新的缓存块采用头插法。
- 空闲地址指针 (free_list) 会串起所有缓存块的地址空间 (单链表)。
- 对象释放后会以头插的形式再次加入到 (free_list)。
隐患:py2.5 之前的版本(之后的不清楚),malloc 出来的缓存块没有一个回收机制,即:创建足够多的对象(malloc 足够多的缓存块)会导致另一种意义上的内存被榨干。
# PyStringObject——python 中的 string 类型
- 字符串的 hash
- 初始为 -1。
- 字符串 hash 采用的算法不够理想,性能消耗较大,会对每个字符进行
乘操作。
- 字符串的特性
- 长度不能超过
(2**32)/2,大概是 21 亿多位,2GB 左右大小。超过则不会创建。
- 长度不能超过
- intern 内存共享
- 针对相同字符串,
不重复创建(其实还是会创建,再销毁),它们共享同一块数据。 - 只会生效在
PyStringObject对象,其子类不会生效。 - 创建新对象时会判断是否已经存在,如果已经存在了,会删除原来创建的对象,然后修改其指针指向。
- 针对相同字符串,
- 字符缓冲区
- 针对单个字符进行缓存,功能类似整数缓存,长度为 (2**8)——256 个字符。
- 初始阶段为空,每次创键新的字符,且不再缓存区内时,进行 intern 操作后,加入进去。
+操作在 string 中执行效率非常低下(string 对象本身是不可变长类型),推荐使用join来一次处理多个。
# PyListObject——python 中的 list 类型
- 形如 c++ 的 vector,本质还是一个数组,分配空间时,多分配一部分,用于动态扩充。
- 管理 list 的指针同样也有一块缓存区,可存储数量是 80 个。如果已经全部占用,则会通过
GC_NEW的方式创建新的。 - 容量调整。在容量不在限制范围内(1/2 容量~容量上限之间)。会进行(扩容 / 缩容)操作,调整方法为:
newsize/8 + (newsize <9 ? 3:6) + newsize - 负值索引的秘诀就在,获取下标的时候针对负数执行
+size操作 - insert 对于 list 来说性能消耗要比 append 高,因为需要后移 insert 之后的元素。
- 对象销毁后会尝试加入缓存区,如果缓冲区满了则释放掉。但是对象管理的内存会被归还。
- 销毁后放回缓冲区的对象会替换原来正在被使用的缓存对象,但是这并不影响。因为被剔除的对象正在被其他对象使用,所以不会被释放。只是不被缓存区管理了。
# PyDictObject——python 中的 dict 类型
- 数据结构是 hashtable,采用开放定址法进行冲突解决(二次探测)。
- 伪删除,字典 key 和 value 被删除时,会暂时保留 key,并且赋值为 dummy,保证能够继续通过探测链找到后续节点。但是也可以对处于 dummy 的 key 进行赋值。相当于占着坑位。
- dict 的 entry 的三种状态
- active(key,val 都不为 null)
- dummy(key 为 dummy,val 为 null)
- unused(key,val 都是 null)
- hashtable 的最初大小为
8,dict 对象的创建同样使用了缓冲池,方式等同于 List。缓存 80 个。 - hashtable 的映射函数是直接用某个对象的 hash 值和 dict 的大小做
与操作保证结果小于等于 dict 大小。 - 判断 key 是否存在需要判断 key 的地址是否相同,不相同再去判断 值的 hash 是否相同,相同再去进行对应的比较。
- hash 匹配失败后的再次 hash 策略:
- 上一个 entry 的 hash 与上容器大小为
i - 第一个 entry 的 hash 为
k - 冲突次数
s - dict 容器大小为
m - 下一个地址公式:
(i * 4 + i + k / (4 * s * 常量) + 1) & m
- 上一个 entry 的 hash 与上容器大小为
- 变更容量操作:
- 装载率:
active和dummy的数量 / 总容量 - 当执行插入操作时,有 Unused 或者 Dummy 对象被填充,并且插入后装载率≥2/3 会进行扩容。
- 变容方式 当前
active的节点数*(active的节点数 > 50000 ? 2 : 4),如果大于 50000 变容为原来 active 节点的 2 倍。否则变容为 4 倍。 - 上面的规则只是期望的变容值,实际结果还需要再次计算,计算方式为 8 的指数增长≥期望变容值。例如期望变容 20,那么最终扩容值会是
8*2*2 = 32 - 判断变容后和之前容量是否为 8,是则不需要变容。否则,分配新内存,把原来的 active 数据插入到新的内存中。释放原有内存。
- 触发缩容的情况:在 active 节点较少,dummy 节点较多,进行插入操作,使得变容条件成立时,触发缩容。python2.7 可能不生效,3.7 可以。
- 装载率:
# python 的编译细节
# pyc 文件
- 运行时的 python 中,字节码会被存储在 PyCodeObject 中。如果一个代码块被其他模块引用(import),python 会首先去寻找对应的 pyc 文件或者 dll 文件,如果没有则会把字节码内容编译到 pyc 内,再 import,pyc 文件。本质上 pyc 文件是 python 运行时对 PyCodeObject 的一个承载。
- pyc 文件保存的内容都是以二进制的形式。记录内容:
- magic number 用于版本控制
- time 时间戳
- PyCodeObject 对象
# PyFrameObject 对象
- 运行时的 python 内部对象。可以理解为 python 中一段 code block 所生成的对象。
- 维护了当前 code block 的全部内容:
- loacl: 本地变量。
- global: 全局变量。
- builtin: 内建变量。
- f_back: 用于返回上一层的指针。
- 维护 PyFrameObject 的「栈」空间:
- f_valuestack: 指向栈的顶部。
- f_stacktop: 指向当前栈顶。
- f_localsplus: 栈起始空间(栈顶等于栈起始空间 + extras)
- extras: 一些指针等额外的空间。
# python 控制流
if控制流 ——compare 操作- if 控制流的跳转操作只能向前。
- 原理:通过
JUMP_IF_FALSE和JUMP_IF_TRUE和JUMP_FORWARD在不同代码片段实现跳转。 - if 控制流通常涉及到比较操作。python 的比较分为
quick_compare和slow_compare,两者速度相差甚远- 快比较适用于两个都是整数类型
- 其他情况下会执行慢比较
- 常见的比较类型:
<>==( is)!=>=<=in
- 慢比较时,如果两个对象类型相同,且不是自定义对象,那么 python 会使用
tp_richcompare比较器进行比较,如果没有定义tp_richcompare或者不满足前面的条件,则会使用用户自定义的tp_compare进行比较。如果上述两个比较器均未实现,python 还会尝试调用do_richcmp进行最后的垂死挣扎,这也是慢比较低下的原因。 - goto 指令:
- JUMP_FORWARD:跳转到
if else语句的最终结尾 - JUMP_IF_FALSE:跳转到对应 false 的逻辑处
- JUMP_IF_TRUE:跳转到对应 true 的逻辑处
- JUMP_FORWARD:跳转到
for控制流- for 控制流的跳转操作可以向前也可以回退。
- 原理:for 语句会把全部对象顺序压入栈中,并把对象的迭代器设置为栈顶,然后通过 SET_TOP 跳转到栈顶,根据迭代器的 tp_iternext 找到对应的元素,进行迭代。
- goto 指令:
- JUMP_ABSOLUTE:回到 FOR_ITER 指令位置,重新开始迭代下一个对象
switch case控制流- 没有了
while控制流- while 和 for 控制流类似。
exception控制流- 异常控制流主要是处理 python 程序在执行过程中如何抛出和捕获异常的控制流。
- 原理:程序执行过程中会构建一个调用栈,当执行到某个函数触发了异常,程序将通过
PyEval_ExalFrameEx函数进行处理,如果没有检测到 except 时, 函数的状态会从WHY_NOT转变为WHY_EXCEPTION,并返回 NULL,同时调整栈指针指向上一层。 - 异常控制流程图:
![image-20200927160601568]()
PyEval_ExalFrameEx函数伪代码:
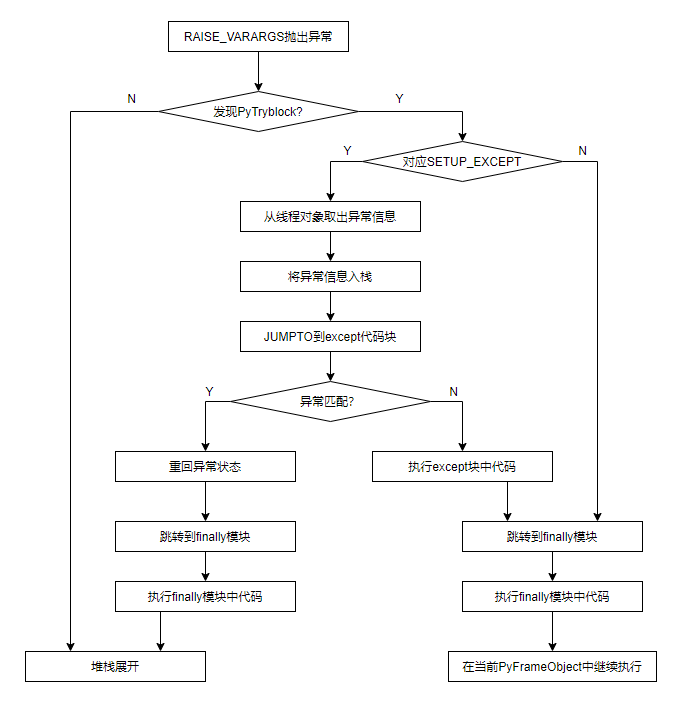
PyObject* PyEval_EvalFrameEx(PyFrameObject *f) | |
{ | |
..... | |
for (;;) | |
{ | |
// 非正常执行 | |
while (why != WHY_NOT && f->f_iblock >0 ){ | |
PyTryBlock *b = PyFrame_BlockPop(f); | |
...... | |
// 有 finally 或者 except 语句 | |
if (b->b_type == SETUP_FINALLY || b->b_type == SETUP_EXCEPT && why == WHY_EXCEPTION){ | |
// 出现异常,先把异常信息取出来,如果后续没有 except,需要保留现场信息并返回给上一级。 | |
if(why == WHY_EXCEPTION){ | |
PyObject *exc, *val, *tb; | |
PyErr_Fetch(&exc, &val, &tb); | |
PUSH(tb); | |
PUSH(val); | |
PUSH(exc); | |
} | |
else { | |
...... | |
} | |
// 设置为正常运转,并调用 except 或 finally | |
//except 执行后会继续在当前栈帧运行(异常被解决) | |
// 无 except 的情况下,finally 执行后会展开到上一层(异常未被解决) | |
why = WHY_NOT; | |
JUMPTO(b->b_handler); | |
break; | |
} | |
} | |
if (why != WHY_NOT) // 不存在异常处理,展开堆栈,抛给上一层 | |
break; | |
} | |
...... | |
if (why != WHY_RETURN) | |
retval = NULL; // 通知前一栈帧有异常 | |
...... | |
// 设置活动栈帧为当前栈帧的上一个,完成栈帧回退 | |
tstate->frame = f->f_back; | |
return retval | |
} |
# 示例 h () -> g () ->f () -> 1/0 | |
def h(): | |
g() | |
def g(): | |
f() | |
def f(): | |
print(1/0) | |
h() |

try catch控制流
# python 函数机制
# PyFunctionObject
PyFunctionObject 对象创建后,随之而来的会创建 PyFrameObject(栈帧) 对象,并为其开辟一块内存空间用于存放函数内用到的各种变量。PyCodeObject 对象则是 PyFunctionObject 对象的静态形式,不保留函数运行时的上下文,只存储基本的信息,而 PyFunctionObject 对象则在程序运行时产生。基本结构如下:
typedef struct { | |
PyObject *func_code; // 对应函数编译后的 PyCodeObject 对象 | |
PyObject *func_globals; // 函数运行时 global 名字空间 | |
PyObject *func_defaults; // 默认参数(tuple 或 NULL) | |
PyObject *func_closure; // NULL or tuple of cell objects, 用于实现 closure(闭包) | |
PyObject *func_doc; // 函数文档 | |
PyObject *func_name; // 函数名称,函数的 __name__属性 | |
PyObject *func_dict; // 函数的 __dict__ 属性 | |
PyObject *func_weakreflist; | |
PyObject *func_module; // 函数的 __module__, 可以是任何对象 | |
} PyFunctionObject; |
- 快速通道:python 为函数的执行提供了一个快速通道,常规的函数
def func(arg1,arg2)可以通过快速通道执行,而 pythonic 形式的函数def func(*args,**kwargs)则无法通过快速通道执行。- 一般位置参数:(√)
- 其他:(×)
# 函数参数实现
# 参数类别
- 位置参数:
- 一般位置参数:
def func(arg1,arg2) - 默认位置参数:
def func(arg1=1,arg2=2)
- 一般位置参数:
- 键参数:
func(arg1=1,arg2=2) - 扩展位置参数:
func(*args) - 扩展键参数:
func(**kwargs)
# 参数数量
- CALL_FUNCTION:通过 2 个字节标识参数数量,高字节表示键参数数量,低字节表示位置参数数量。所以函数最多可以有 256 个位置参数和 256 个键参数。值得注意,该问题在 python3.7 之后已经没有了。唯一限制数量的因素:
list,tuple和dict仅受限于sys.maxsize*args和**kwargs仅受限于sys.maxint*args和**kwargs都只占用一个参数数量,在编译时会被处理成PyListObject和PyDictObject
# 参数位置
函数参数和运行时栈的空间,在逻辑上是分离的,参数会被存放在 f_localsplus 中。而 PyFrameObject 则保存了 f_localsplus 的栈顶指针。
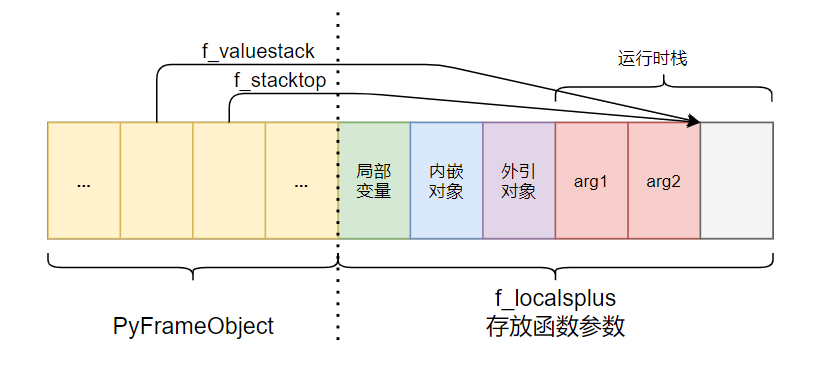
# 扩展参数
扩展参数申明后,会提供一个标记,用于函数读取参数时区分是否需要处理扩展参数:
- 扩展位置参数:CO_VARARGS
- 扩展键参数:CO_VARKEYWORDS
# 函数内变量
函数内的变量和函数参数类似,都是存放在 f_localsplus 中运行时栈前面的一段内存空间中
# 嵌套、闭包、装饰器
# 嵌套函数
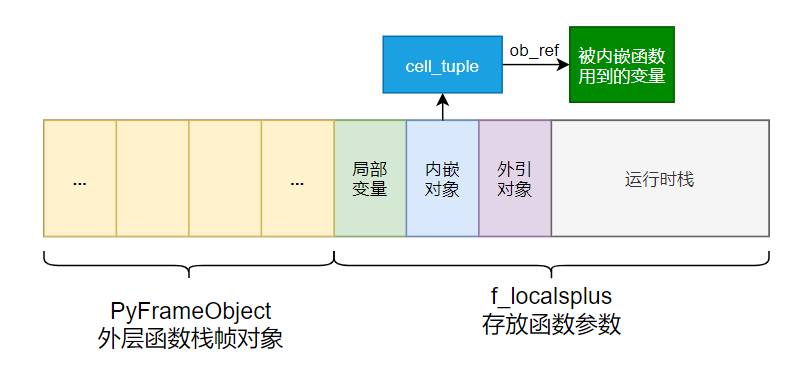
- co_cellvars:通常是一个 tuple,保存嵌套作用域中使用到的变量名集合,存放在
f_localsplus的内嵌对象中。 - co_freevars:通常是一个 tuple,保存了使用外层作用域的变量名集合,存放在
f_localsplus的外引对象中。
def out(): | |
i = 1 | |
def in(): | |
print(i) | |
return in |
该嵌套函数中 out 函数中的 co_cellvars 内会保存 i 变量,同理 in 函数中的 co_freevars 内也会保存 i 变量。
# 闭包(closure)
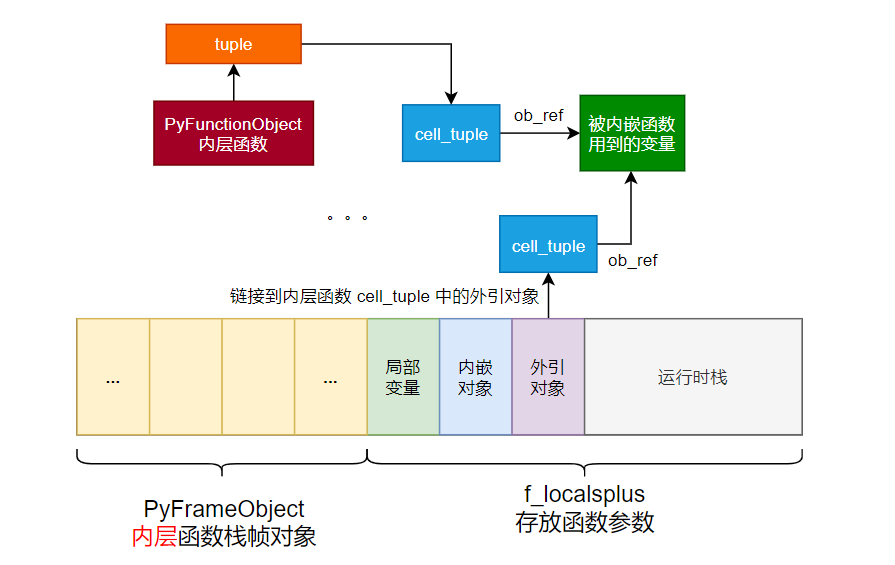
当内层函数使用外层函数的变量的这种形式被称之为闭包,闭包的实现原理大致可以理解为:
- 外层函数在执行过程中,会把自身运行栈中的变量以
ob_ref的形式绑定到co_cellvars的 tuple 当中。![image-20200928212157054]()
- 在需要向内层传递时,首先会创建一个内层函数的对象,存储在局部变量上 inner_func,并把
co_cellvars的 tuple 链接到 inner_func 对象的 tuple 上。
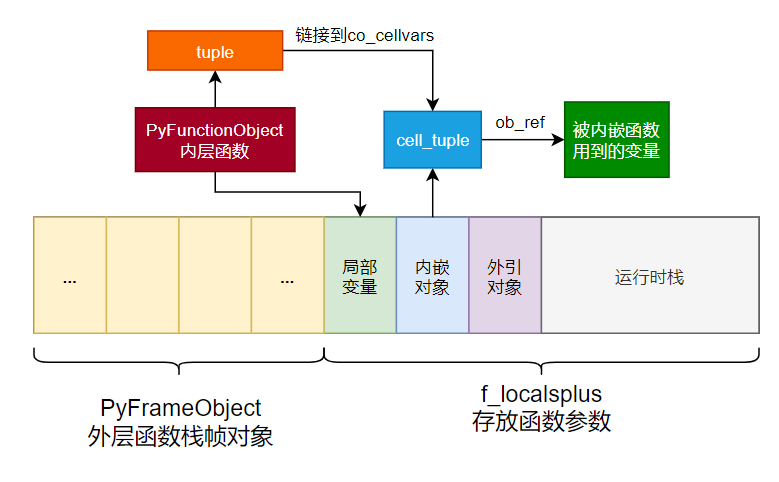
- 最终,在 inner_func 对象内,解开传递进来的
co_cellvars的 tuple 并重新绑定到自己的co_freevars的 tuple 中,便完成了整个闭包的参数传递过程
# 装饰器(decorator)
装饰器本质上就是闭包的一个包装方式,原理和 closure 类似。
# python 类机制
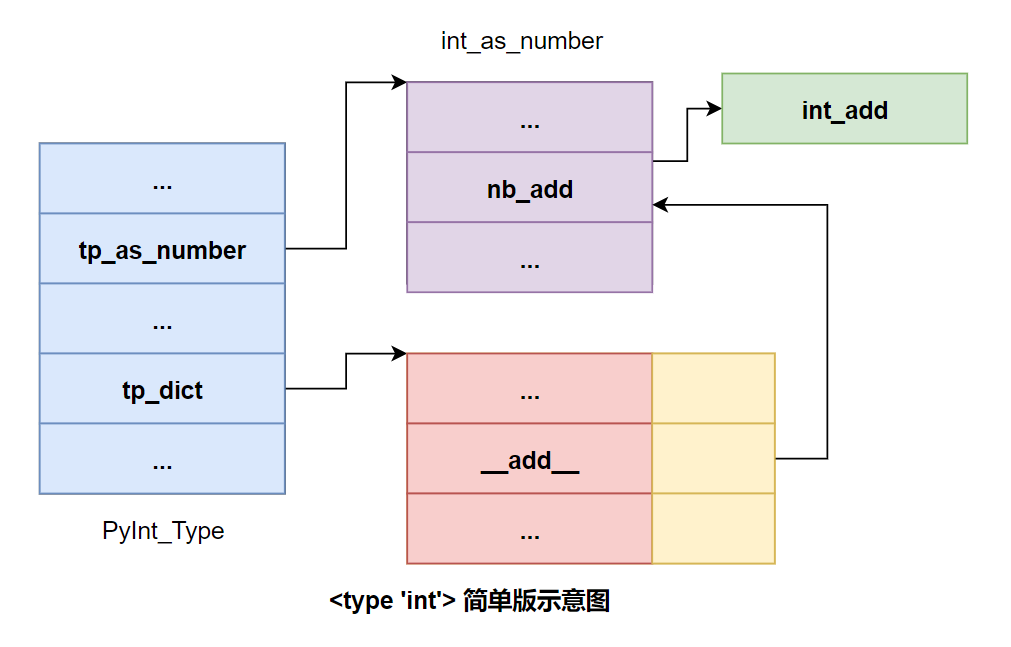
Python 中,任何对象都有一个
type,可以通过__class__属性获得,任何一个instance对象的type都是一个class对象。任何一个class对象的 type 都是一个 metaclass 对象。大多数情况下metaclass对象通常是<type 'type'>。Python 中,任何 class 对象都直接或间接与
<type 'object'>存在is-kind-of(基类与子类) 关系,包括<type 'type'>。
# 从 type 对象到 class 对象
class MyInt(int): | |
def __add__(self, other): | |
return int.__add__(self, other) + 10 |
# 可调用性(callable)
只要一个对象实现了 __call__ 操作,本质是是 Python 内部的 PyTypeObject 中的 tp_call 不为空,那就其就是一个可调用对象
# Step.1 处理基类 ( class.__base__ ) 和 Type 信息
int PyType_Ready(PyTypObject *type){ | |
PyObject *dict *bases; | |
PyTypeObject *base; | |
Py_ssize_t i,n; | |
//「1」:尝试获得 type 的 tp_base 中的指定基类。 | |
base = type ->tp_base; | |
if(base == NULL && type != &PyBaseObject_Type){ | |
base = type->tp_base = &PyBaseObject_Type; | |
} | |
//「2」:没有初始化基类的话,初始化基类 | |
if(base && base->tp_dict == NULL){ | |
PyType_Ready(base) | |
} | |
//「3」:设置 type 信息 | |
if(type->ob_type == NULL && base != NULL){ | |
type->ob_type = base->ob_type; | |
... | |
} | |
} |
部分内置函数的 tp_base 信息,NULL 的话则默认为
<type 'object'>(PyBaseObject_Type)
| class 对象 | 基类信息 |
|---|---|
| PyType_Type | NULL |
| PyInt_Type | NULL |
| PyBool_Type | &PyInt_Type |
# Step.2 处理基类列表 ( class .__bases__ )
int PyType_Ready(PyTypObject *type){ | |
... | |
//「4」: 处理基类列表 | |
bases = type->tp_bases; | |
if(bases == NULL){ | |
if(base == NULL) | |
bases = PyTuple_New(0); | |
else | |
bases = PyTuple_Pack(1, base); | |
type->tp_bases = bases; | |
} | |
} |
# Step.3 填充 tp_dict ( class .__dict__ )
int PyType_Ready(PyTypObject *type){ | |
... | |
//「5」: 设定 tp_dict | |
dict = type->tp_dict; | |
if (dict == NULL){ | |
dict = PyDict_New(); | |
type->tp_dict = dict; | |
} | |
//「6」: 将与 type 相关的 descriptor 加入到 tp_dict 中 | |
add_operation(type); | |
if(type->tp_methods != NULL){ | |
add_methods(type, type->tp_methods); | |
} | |
if(type->tp_members != NULL){ | |
add_members(type, type->tp_members); | |
} | |
if(type->tp_getset != NULL){ | |
add_getset(type, type->tp_getset); | |
} | |
... | |
} |
# Step.4 对 slot 排序并关联到 descriptor
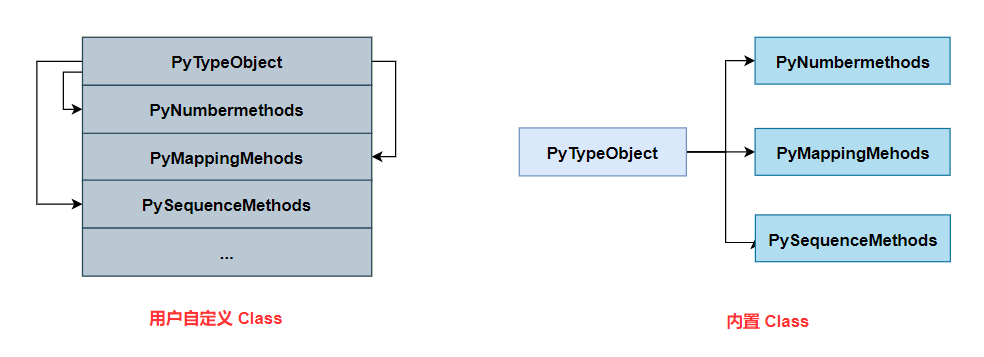
每个
descriptor对应与一个slot。一个slot对应一个func。而每个函数又通过函数名和descriptor指针被关联在PyTypeObject对象中的tp_dict内。如果出现一个函数名对应多个
slot的情况下时。slot排序可以解决最终调用哪个的问题。排序规则则是根据offset大小来决定的,offset小的优先级更高。 例如两个同名函数,一个在PyHeadObject的PyNumberMethods结构中,另一个则在PyMappingMethods中,那么PyNumberMethods中的将被调用。调用函数时,会先在
PyTypeObject的tp_dict内进行查找,根据函数名找到对应的descriptor,并调用descriptor的wrapperdescr_call调用slot所关联的func
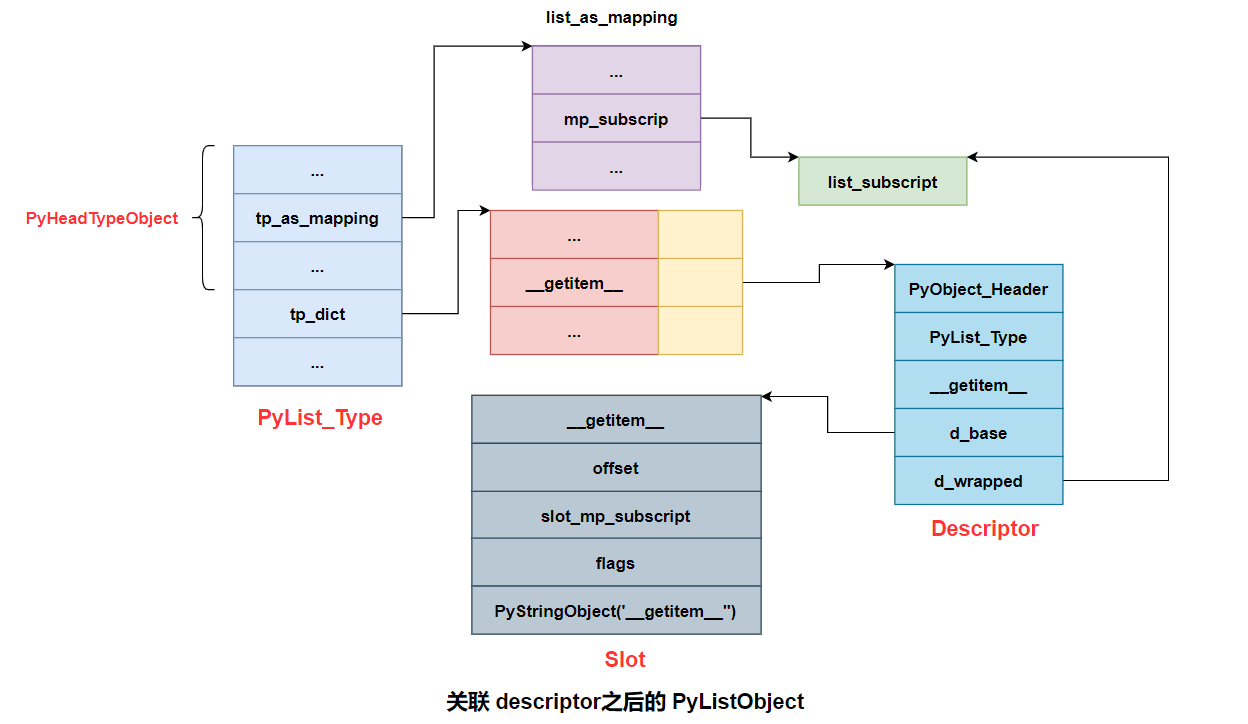
slot 结构
struct slotdef{ | |
char *name; // 函数名称 | |
int offset; // 相对于 PyHeadObject 的偏移量 | |
void *function; //slot 的 function | |
wrapperfunc wrapper; | |
char *doc; | |
int flags; | |
PyObject *name_strobj; | |
} |
descriptor 结构
struct PyWrapperDescrObject{ | |
PyObject_HEAD | |
PyTypeObject *d_type; | |
PyObject *d_name; | |
struct slotdef *d_base; //slot 对象 | |
void *d_wrapped; // 关联的函数指针 | |
} |
PyHeadTypeObject 结构
struct PyHeadObject{ | |
PyTypeObject ht_type; | |
PyNumberMethods as_number; | |
PyMappingMethods as_mapping; | |
PySequenceMethods as_sequence; | |
PyBufferProcs as_buffer; | |
PyObject *ht_name, *ht_slots; | |
} |
# Step.5 确定 mro 列表
mro 的 C3 超类线性化算法:
算法思想:
- 对象父类的集合
「L(自己)」可以视作「自己」+ 每个「L(父类)」+「父类集合」 - 在存在多个父类合并的情况下,优先提取出第一个集合中的第一个元素与其他集合进行比对,如果其同时出现在其他集合的
非第一的位置则跳至下一个集合重复上述操作。否则则把该元素添加至父类列表,并从其余所有集合中移除,完成后再次从第一个集合提取第一个元素重复上述内容。
.png)
L(O) = [O] | |
L(C) =[C,O] | |
L(A) =[A,O] | |
L(B) =[B,O] | |
L(D) =[D,O] | |
L(E) =[E,O] | |
L(K1) = [K1] | |
+ L(C) | |
+ L(A) | |
+ L(B) | |
+ [C,A,B] | |
L(K1) = [K1] | |
+ [C,O] | |
+ [A,O] | |
+ [B,O] | |
+ [C,A,B] | |
L(K1) = [K1,C,A,B,O] | |
L(K2) = [K2,A,B,D,O] | |
L(K3) = [K3,B,D,E,O] | |
L(Z) = [Z] | |
+L(K1) | |
+ L(K3) | |
+ L(K2) | |
+ [K1,K2,K3] | |
L(Z)= [Z] | |
+ [K1,C,A,B,O] | |
+ [K2,A,B,D,O] | |
+ [K3,B,D,E,O] | |
+ [K1,K2,K3] | |
L(Z) = [Z,K1,K2,K3] | |
+ [C,A,B,O] | |
+ [A,B,D,O] | |
+ [B,D,E,O] | |
L(Z) = [Z,K1,K2,K3,C,A,B,D,E] | |
+ [O] | |
+ [O] | |
+ [O] | |
L(Z) = [Z,K1,K2,K3,C,A,B,D,E,O] |
# Step.6 继承基类操作
int PyType_Ready(PyTypObject *type){ | |
... | |
//「7」: 拷贝基类操作到子类 | |
bases = type->tp_mro; | |
n = PyTuple_GET_SIZE(bases); | |
for (i = 1; i < n; i ++){ | |
PyObject *b =PyTuple_GET_ITEM(bases, 1) | |
inherit_slots(type, (PyTypeObject *)b); // 拷贝 | |
} | |
... | |
} |
# Step.7 填充子类列表( class.__subclasses__() )
int PyType_Ready(PyTypObject *type){ | |
... | |
//「8」: 填充子类列表 | |
bases = type->tp_mro; | |
n = PyTuple_GET_SIZE(bases); | |
for (i = 1; i < n; i ++){ | |
PyObject *b =PyTuple_GET_ITEM(bases, 1) | |
add_subclass((PyTypeObject *)b, type); // 填充 | |
} | |
... | |
} |
# 自定义 class
创建 class 对象
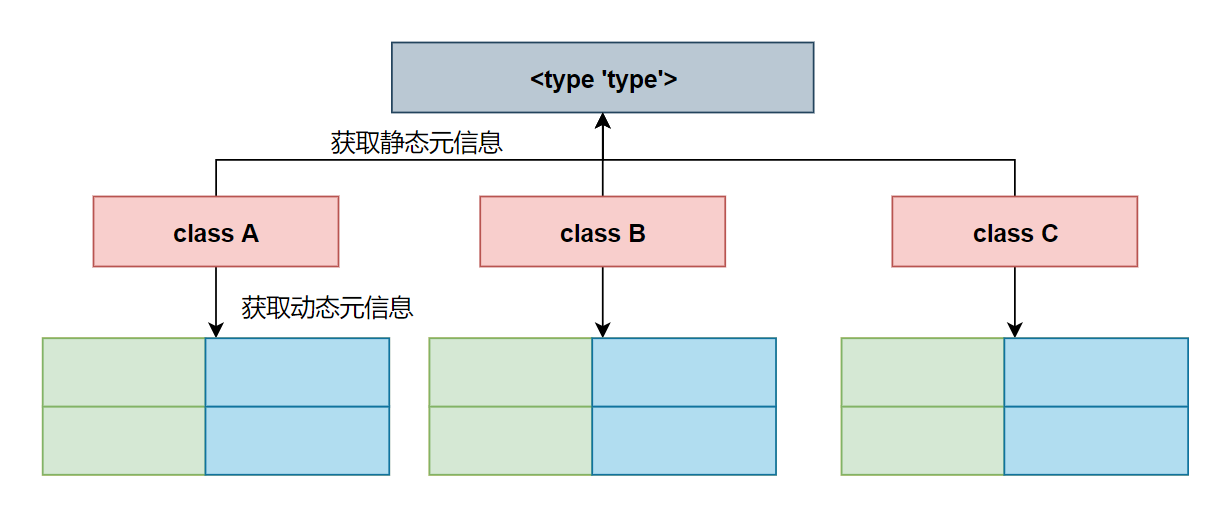
- 获取动态元信息 ——class 的动态属性(属性,函数)
- 获取静态元信息 ——class 的类型,空间大小(通过查看
_metaclass__属性来获取静态元信息,默认情况下是获取<type 'type'>的静态元信息)![image-20201005153723438]()
- 用户自定义 class 对象和内置 class 对象的区别在于:
- 用户自定义对象的内存排列是连续的
- 内置 class 对象的内存排列是分散的
![image-20201005154812793]()
创建 class 对象的 instance
instance = class.__new__(class, args, kwds)class.__init__(instance, args, kwds)
# descriptor 介绍
descriptor 像是一个连接属性名称和属性值的一个接口。提供一套访问属性的方法。外部通过 descriptor 来对属性进行访问。
- 实现了
__get__、__set__、__delete__函数的 obj 被称之为descriptor descriptor影响着class和instance对于属性的获取规则- 有
__get__和__set__的被称为data descriptor - 有
__get__无__set__的被称为no data descriptor
- 有
- 属性选择的规则:
- 先
instance的属性,后class的属性。 - 如果
instance和class中有同名属性,且class的属性是data descriptor,那么会选择使用class的属性。 - 当获取到的属性是一个
descriptor的时候,如果其存在于class的tp_dict中会调用其__get__函数获取对应的属性值,如果其存在于instance的tp_dict中则不会调用其__get__属性。
- 先
# Bound Method 和 Unbound Method
两者的本质区别是一个函数的调用是否有默认参数 self。如果有,则在每次函数调用过程中,虚拟机会自动执行一次函数绑定,把 instance 和 self 进行关联。否则,需要程序自己手动传参。
class A: | |
def test(self): | |
... | |
a = A() | |
a.test() # 自动绑定 | |
A.test(A()) # 手动传参 |
减少函数绑定的次数可以提高程序的执行效率
func = a.test #绑定 1 次 | |
for i in range(1000): | |
func() | |
for i in range(1000): | |
a.test() #绑定 1000 次 |
# python 运行环境初始化
# 初始化线程环境
- 初始化 python 多进程
- 初始化 python 多线程
# 进程结构:
// 进程对象结构 | |
struct PyInterpreterState{ | |
struct _is *next; | |
struct _ts *tstate_head; // 模拟线程集合 | |
PyObject *modules; | |
PyObject * sysdict; | |
PyObject *builtins; | |
} |
# 线程结构:
// 线程对象结构 | |
struct PythreadState{ | |
struct _ts *next; | |
PyInterpreterState *interp; | |
struct _frame *frame; // 模拟函数调用栈 | |
int recursion_depth; | |
... | |
PyObject *dict; | |
long thread_id; | |
} |

# 加载系统 module
# 创建 __builtin__ module
一个进程内的全部线程共享一个 <module __builtin__>
- 创建 module 对象
- 设置 module 对象

# 创建 sys module
- 创建 sys module 并备份
- 设置 moduel 搜索路径
- 创建
__main__module - 设置 site-specific 的 module 搜索路径(第三方库)
- 核心实现在 site.py 中:
- site 会将 site-packages 加入到 sys.path
- 把 site-packages 下的所有 .pth 文件加入到 sys.path 中
- 核心实现在 site.py 中:

extensions 用于缓存模块,再次加载的时候可以提高效率。
# 激活虚拟机
# 交互式运行方式
- 把用户输入构造成 python 的 AST 语法树
- 执行 run_mode 运行语法树
# 脚本文件运行方式
- 编译脚本文件
- 执行 run_mode 运行编译后的脚本文件
# 启动虚拟机
- run_mode 内会启动 Python 字节码虚拟机。之后循环往复的执行字节码。
# 名字空间
- local、global、bulitin 的设置。
- 交互环境下 local 名字空间内不会有
__file__属性 - Python 所有的线程都共享同样的 builtin 名字空间
# python 模块动态加载机制
# import 机制
import module/package:import操作会先在全局模块池(sys.module)中搜索module或package。如果以及存在,则直接加入当前module的local名字空间,否则就添加到sys.module和local。import package.module:和import module/package类似,不过会额外把package加入到sys.module中。但不会加入local名字空间。import package.module as xx:和import package.module类似。这里会对package.module在local名字空间做一个映射,实际的sys.module中引入的还是package.module。但是在local中其表示为xx。from package.module import xx:和import package.module as xx类似。会在sys.module引入package和package.module,同时在local引入xx。- 嵌套的
import:一个模块 import 另一个模块的情况下。每个模块的 import 都会影响sys.module和自身的local名字空间。但不会影响其他模块的local。
# 模块销毁与重载
# 销毁
Python 提供了 del module/package 操作用于销毁模块。但是销毁的只是当前 local 名字空间内的, sys.module 中依旧保存了其缓存。所以单纯的 del module ,再 import module 并不能实现热更新。
# 重载
Python 提供了 reload module 操作用于重载模块。 reload 操作可以更新 sys.module 中的模块信息,把一些新增和修改的内容加入到 module 中,但是对于需要删除的内容,则无能为力,依旧会缓存在 module 内。
# import 实现机制
import 的实现核心是依靠其 builtin 模块内的 __import__ 操作。即: builtin__import__ 函数。
- 调用
builtin__import__函数,解析传递进来的参数。 - 上锁。避免不同线程同时操作一个
module。 - 解析
module/package树状结构。- Python 的所有搜索操作(
import xxx/from xxx import xxx)都是基于某一个package来的。换句话说,所有查找的根目录(__main__) 都是一致的。即:某个package的路径。 - Python 的搜索操作是不能搜索根目录之上的模块,例如:
- Python 的所有搜索操作(
# 如果是基于 Package——A,那么可以访问到所有模块。根路径:/A = __main__.path | |
# 如果是基于 Package——B,那么无法访问 C 模块和 A 模块下的内容。根路径:/A/B = __main__.path | |
# 如果是基于 Package——C,那么无法访问 B 模块和 A 模块下的内容。根路径:/A/C = __main__.path | |
A | |
|——__init__.py | |
|——B | |
| |——__init__.py | |
| |——test1.py | |
| |——test2.py | |
|——C | |
| |——__init__.py | |
| |——test3.py | |
| |——test4.py |
- 加载
module/package先在
sys.module中搜索是否依旧有加载过该模块留下的缓存了。尝试加载
source module。如果没有则对.py文件进行编译,生成所需的PyCodeObject。如果需要加载内建 module。则会先去内建 module 备份列表中确认是否以及加载过了。再执行加载操作。
加载 C 扩展的 module。
- window:dll 文件
- linux:so 文件
- 不论哪种平台,都需要遵循 Python 执行的一套导入规则,格式大致如下:
// 申明一个 PyMethodObject 对象所需的参数信息static PyMethodDef test_methods[] = {
{"hello", Hello, METH_VARARGS, "say hello"}, // 对应下方图片内红框内容
{NULL, NULL}
};
// 告知 Python 初始化模块:模块名 模块信息EXPORT int initest(void){
Py_InitModule("test", test_methods);
return 0;
}- 细心的同学可以发现,这和内建模块的导入规则几乎一致

from xxx import m,n:该操作会判断 xxx 模块中是否存在 m 和 n,而判断的依据就是通过__all__来实现的。如果没有申明__all__,那么则会使用 Python 默认的PyObject_GetAttrString函数来获取模块下的所有内容。否则,则会以__all__列表里的内容为准。
# LEGB 规则
Local -> Enclosed -> Global -> Built-in
Local:可能是在一个函数或者类方法内部。Enclosed: 可能是嵌套函数内,比如说 一个函数包裹在另一个函数内部。Global:代表的是执行脚本自身的最高层次。Built-in:是 Python 为自身保留的特殊名称。
# 最内嵌作用域 规则
由一个赋值语句引进的名字在这个赋值语句所在的作用域里是可见(起作用)的,而且在其内部嵌套的每个作用域里也可见。
除非它被嵌套于内部的,引进同样名字的另一条赋值语句所遮蔽 / 覆盖。
- eg:
[module2.py] | |
a = 50 | |
def test(): | |
print(a) | |
[module1.py] | |
import module2 | |
a = 100 # module1 申明的 a 在 module2 中是可见的 | |
module2.test() #执行过程中 module2 里的 a 覆盖了 global 作用域中 module1 里的 a | |
Out:50 |
# python 多线程机制
# GIL (全局解释器锁) 和线程调度
在 Python 多线程中,不同线程之间会访问一些共享的资源,例如对象的引用计数和对象的释放。如果同时有两个线程修改一个对象的引用计数,导致对象被释放,那么可能会出现对象释放多次的问题。这时 GIL 就应运而生了。
GIL:本质上是一个解释器,只有当线程拥有该解释器的访问权限时,才能够执行指令。GIL间接的把多处理器的多线程模型转变为了单处理器的多线程模型。虽然其看上去对于锁的粒度较大,但在实际使用中效果却意外的好用。- 线程调度:
- 中断机制:Python 的中断机制和操作系统类似,都是模拟
时钟中断。会根据执行的指令数目来控制线程中断,在 Python 2.5 中,默认执行 100 条指令后,会触发线程的中断,切换到其他线程。 - 唤醒机制:对于需要唤醒哪个线程,Python 层面没有过多的干涉,而是把该任务交给了操作系统。
- Python 提供的两个多线程工具:
- thread:C 实现的 builtin module。
- threading:Python 实现的标准库 module。
- 中断机制:Python 的中断机制和操作系统类似,都是模拟
# Python 线程的创建
Python 虚拟机默认情况下是不支持多线程的,即:用户如果没有手动调用 thread.start_new_thread 接口,Python 则不会创建多线程相关的对象,也不会触发线程调度。
static PyObject* thread_PyThread_start_new_thread(PyObject *self, PyObject *fargs){ | |
PyObject *func, *args, *keyw = NULL; | |
struct bootstate *boot; | |
long ident; | |
PyArg_UnpackTuple(fargs, "start_new_thread", 2, 3, &func, &args, &keyw); | |
// 「1」: 创建 bootstate 结构 | |
boot = PyMem_NEW(struct bootstate, 1); | |
boot->interp = PyThreadState_GET()->interp; | |
boot->func = func; | |
boot->args = args; | |
boot->keyw = keyw; | |
// 「2」: 初始化多线程环境 | |
PyEval_InitThreads(); | |
// 「3」: 创建子线程 | |
ident = PyThread_start_new_thread(t_bootstrap, (void*) boot); | |
return PyInt_FromLong(ident); | |
} |
创建线程主要分为三个步骤:
- 创建并初始化 bootstate 结构 boot,boot 中保存了线程的过程和过程的参数。
- 初始化 Python 的多线程环境。
- 以 boot 为参数,创建操作系统的原生线程。
# 建立多线程环境
- 创建 GIL,以下是 GIL 的结构
struct NRMUTEX{ | |
LONG owned; //GIL 是否可获得,或是被占用 -1: 可用 0: 被占用 | |
DWORD thread_id; // 线程 id | |
HANDLE hevent; // 操作系统的 Event 对象 | |
} |
- 线程每次需要执行前,必须获取 GIL,通过
PyThread_acquire_lock函数。PyThread_acquire_lock有两种工作方式:- 当无法获得 GIL 时,挂起自身。
- 无法获得 GIL 时,不挂起。
# 子线程的创建步骤
- 创建 bootstate 结构。
- 初始化多线程环境(主线程获得 GIL 控制权)。
- 创建子线程,同时挂起主线程,子线程开始完成 bootstrap 线程过程。这里的主线程挂起,子线程执行线程过程的操作不在 Python 中断的范畴,而是利用了操作系统本身的中断机制。所以子线程不需要获取 GIL 的控制权。
- 完成之后获得 thread_id,并设置 Semaphore,返回 thread_id ,挂起自身,并唤醒主线程。
- 主线程获得子线程的 thread_id,并开始和子线程争夺 GIL 的控制权(通过
时钟中断)。此时,主线程和子线程的中断才完全依赖 GIL 的控制权控制。 - 当子线程获得 GIL 控制权,主线程请求 GIL 被占用时,主线程挂起自身,子线程开始执行,当子线程执行完全部内容后,将被释放。到此,子线程的生命周期就已经结束。
在子线程没有完全的创建完毕前(第 4 步没有执行完毕),中断机制不受 GIL 控制。
线程自身的挂起状态,不是在归还 GIL 控制权后发生,而是在请求 GIL 无果后发生。
# 线程状态保护机制
为了能够快速访问线程的状态,获取每个线程的信息,Python 为线程状态链表单独实现了一套锁机制,并且线程状态链表的访问不受 GIL 控制。

# Python 线程调度
# 标准调度
通过字节码计数来触发中断,默认情况下线程每执行 100 条字节码指令,就会触发一次中断。但在 Python 程序中,某些指令的执行不会计算字节码执行次数。
# 阻塞调度
阻塞调度和标准调度有所不同,标准调度的中断触发是被动的,而阻塞调度的中断触发则是主动的,即:线程主动归还 GIL 的控制权。且诸塞调度完成后不会把字节码指令数重置成 100。
此外相比于标准调度在切换线程时的连续性,阻塞调度在主动归还 GIL 到下次某个线程获得 GIL 的中间段,是会有一个空窗期的,这段时间内,线程将脱离 GIL 的控制,不过好在这段时间内,没有涉及到 Python 的 C API 调用,所以是线程安全的。
# Python 子线程的销毁
线程的销毁会释放其占用的 GIL 以及一些线程资源和维护的线程状态链表对象。
此外,主线程的销毁同时也会销毁 Python 的运行时环境,而子线程则不会。
# Python 线程的用户级互斥与同步
# Lock 对象
Python 的 Lock 分为系统级的 Lock——GIL 和 用户级 Lock。
当线程被唤醒时,首先会获得系统级的 Lock (GIL) 的控制权,之后会尝试获取用户级 lock,如果用户级 lock 被占用,则线程会归还系统级控制权,避免死锁。
# 高级线程库 ——threading
# Threading Module 概述
threading module 维护了两个 dict 和一个 lock:
- 准备创建的线程字典:
_limbo[thread] = thread - 已经创建的线程字典:
_active[thread_id] = thread - 访问线程状态链表的锁:
_active_limbo_lock
# Threading 的线程同步工具
RLock:正常的 lock 一个 acquire 对应于 一个 release,如果同时执行两个 acquire 而不 release,则会出现死锁。RLock 则提供了可用多次 acquire 后再多次 release 操作的机制。不必每次借钱之前都得把上次欠的还清,可以先借多次,再还多次。Condition:本质上时一个Lock对象,默认情况下是RLock,提供了wait和notify操作,可用在别的线程中主动唤醒其他线程。ConditionA.wait:A 线程调用时,释放ConditonA中的Lock并挂起线程 A。ConditionA.notify:其他线程调用时,获得ConditonA中的Lock并唤醒线程 A。
Semaphore:类似信号量,实现机制也是基于Lock,内部维护一个Conidtion对象,但与 Lock 的互斥不同,其可以支持多个线程获得资源。资源池的概念。Event:和 Semaphore 类型,提供set和wait语义。
# python 的垃圾回收 GC
# block
- 用于存放对象的最小单位。
- 针对不同 size 的数据进行分类存储的块。数据大小为 8 的整数倍,最大为 256 字节。
- 如果内存大小≤256,则 python 会通过 PyObject_Malloc 去分配。如果 > 256 字节,则会使用 malloc 来分配内存。
- size 有 32 种(0~31)之后的版本扩充到了 63(512 字节)。
- 给对象分配的空间一般会超过原本大小,向上取 8 的整数倍。
.png)
# pool
同一个 pool 中的 block 大小必须统一。
![7b94ea10747352b5100ca504cdf76571.png]()
pool 的大小一般为 4kb。
管理 block 的指针分为四种:
- bp 指针:指向当前使用 block。
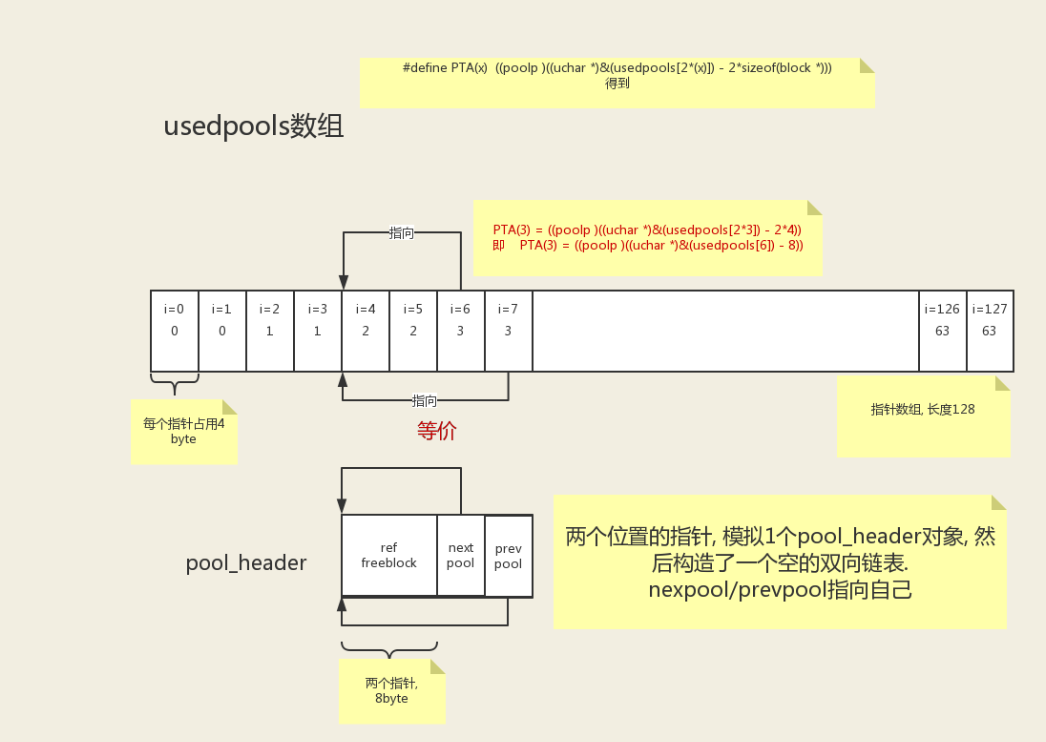
- free 指针:指向下一个可用 block,free 是一个链表,每个节点内的值为 Null 或者是下一个空闲的 block 地址。
- next 指针:指向 free 的下一个空闲 block,一般是在当 free 内的值为 Null 的情况下,系统申请新空闲 block 后,给 free 作定位用的。
- maxnext 指针:指向 block 的最后一个 block 的首地址。用于判断 block 是否已经全部分配完毕。
![ba149b720cee23ad2d08f6d95bb29524.png]()
pool 的结构是由一个 pool_header 和一堆 block 组成的数组。它们是一个整体。
pool 的状态:
- used 状态。pool 中即存在被使用的 block,也存在未被使用的 block。
- full 状态。pool 中所有 block 都在被使用。
- empty 状态。pool 中所有 block 都未被使用。
usedpools。所有正在被使用的 pool 的双向链表头。本身是一个 pool_header * 组成的数组,通过一点取巧的方式把每个指针和其前面 2 个位置的指针一起视为一个 pool_header 对象从而构成一个空的双向链表。
.png)
.png)
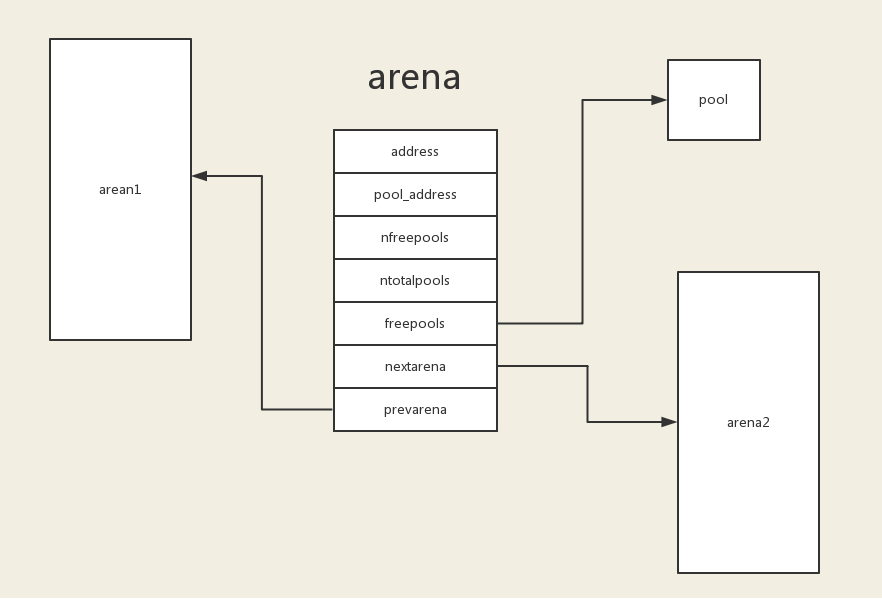
# arena
多个 pool 的管理者,每个 arena 的 pool 可以存在多个不同的
size class index。![image-20200919154538226]()
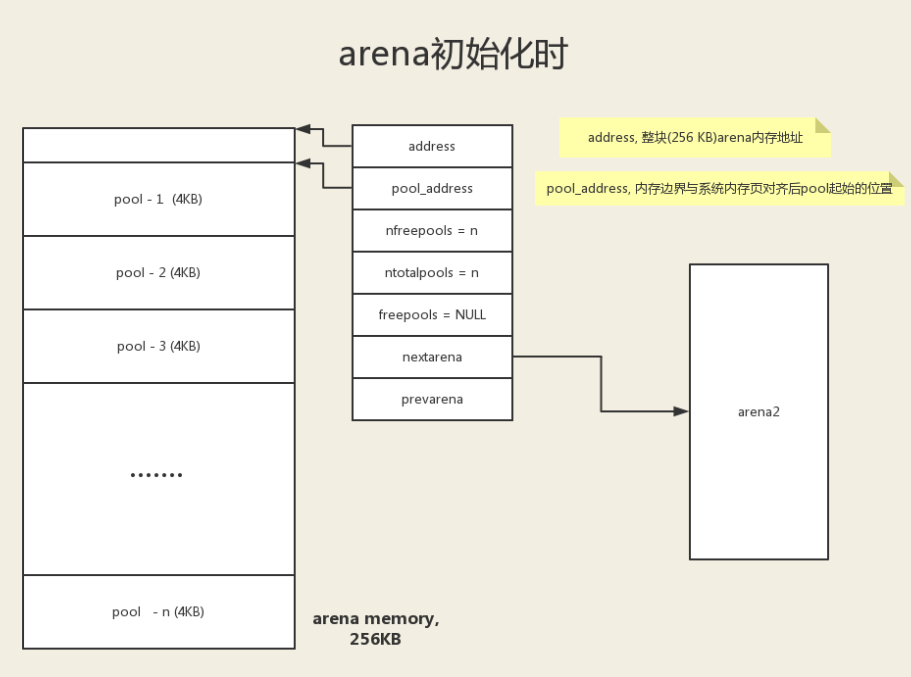
一个 arena 的大小为 256k,可容纳 64 个 pool。
![image-20200919154553555]()
arena 的结构是由一个 arena_object 指针和一堆 pool 组成的数组构成。不像 pool 一样,arena 的指针和内存是分离的。
arena 有两种状态
- 未使用状态:arena_object 指针没有指向对应的 pool 组成的数组块。
- 使用状态:arena_object 指针已经指向对应的 pool 组成的数组块。
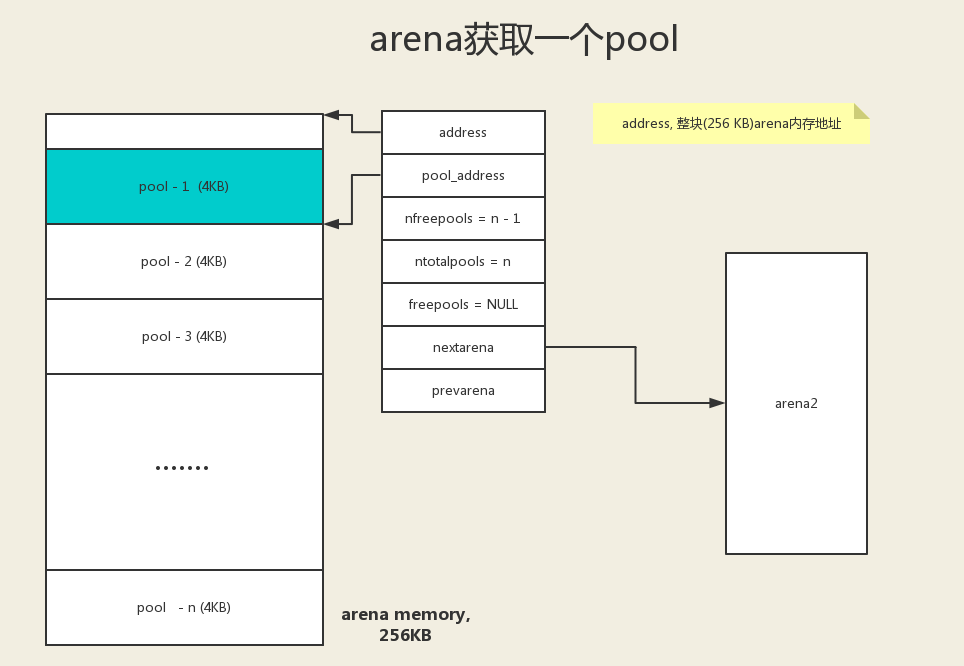
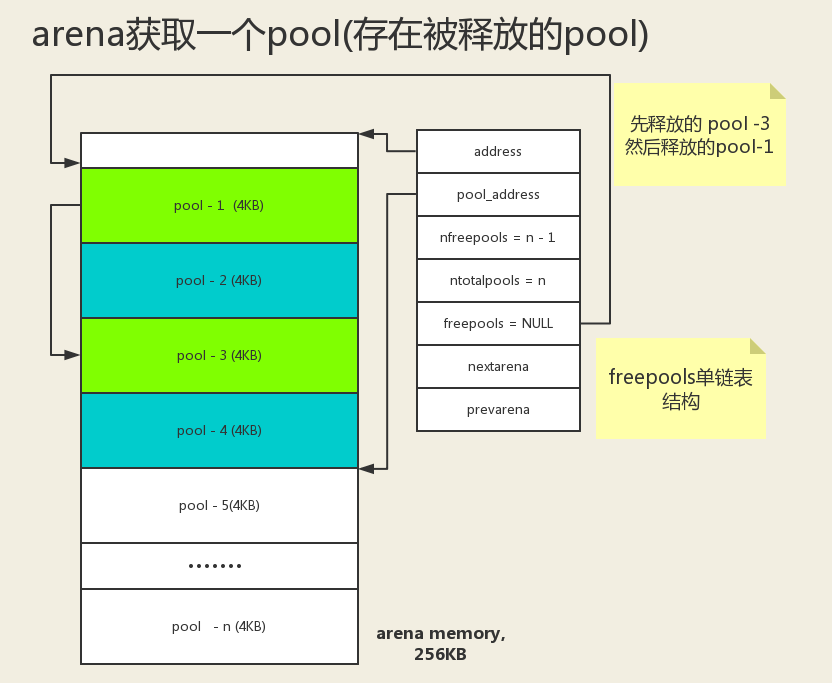
# arenas
- 管理多个 arena 的对象指针的数组。
- 把 arena 分为两种状态:
- 未使用状态:通过 arenas 的 unused_arena_objects 指针作为表头的单向链表所连接
- 使用状态:通过 arenas 的 used_arena_objects 指针作为表头的双向链表所连接
- 多个 arenas 通过名为 nextarena 和 prevatrena 的指针所联系在一起。
- 初始化时创建的 arena 的数量为 16 个。之后如果未使用的 arena 不足时,会进行二倍的扩容。
- 扩容操作只会创建 arena 的指针,只有在 arena 将要被使用时,才会去分配一个 256k 的大小。
- 当前管理的 arena 的总数是由一个 int 类型的变量控制。每次扩容左移一位。当发生溢出(超过 2**32 或者分配的空间不足一个 arenas 的大小)时停止扩容操作。
![image-20200919154653554]()
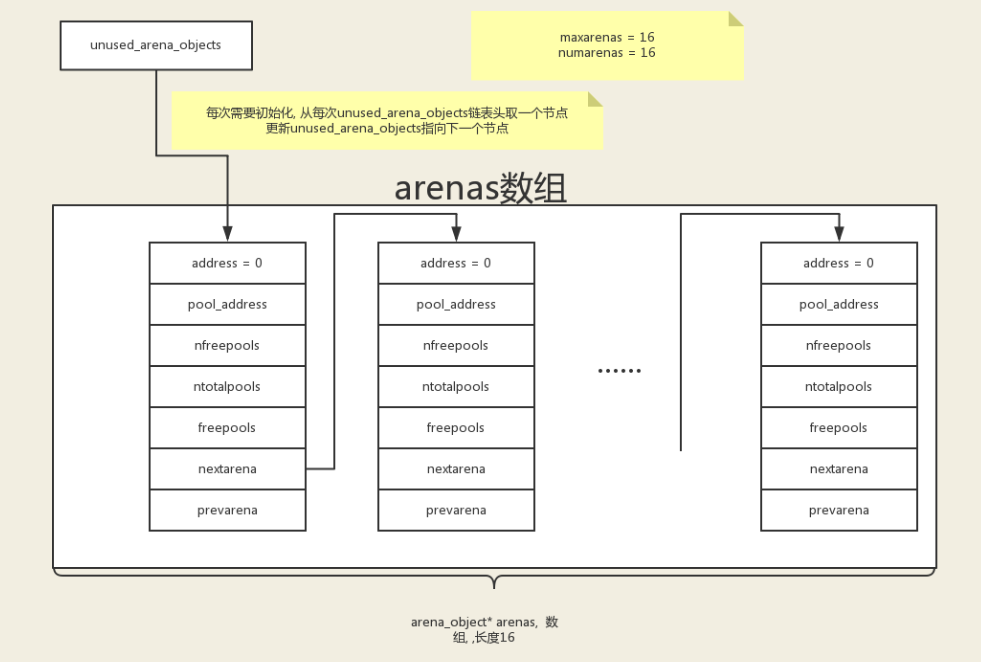
参考:http://wklken.me/posts/2015/08/29/python-source-memory-1.html
参考:http://wklken.me/posts/2015/08/29/python-source-memory-2.html
# 垃圾回收(GC)
# 1、标记清除(Mark——Sweep)
- 寻找根对象集合
- 采用双向链表存储所有 container 对象
- 为此每个 container 对象头部都存在一个 PyGC_Head 的数据块(在 PyObject_Head 之前)
- 寻找可达对象和不可达对象
- 广度探测
- 对于非 container 对象不进行检查
- 一个对象如果不能存储其他对象的引用则被视为非 container 对象
- 对于可达对象进行保留,不可达对象进行回收。
# 2、分代的垃圾收集 ——python 的解决办法
核心思想:
- 根据内存的创建时间划分为不同的「代」
- 时间越「长」的对象其被回收的概率就「小」。
- 经过多次垃圾回收「存活」下来的对象则会被分配到回收周期更「长」的代中。
- 每个「代」在 python 中对应的是一个「链表」,python 总共把代分为三个。
- 第「0」个代的链表长度超过 700 时会触发垃圾回收(第一、二代都是 10)。python 还会借此机会清理其他的代。
- python 对代的清理是通过把第 2 代到第 0 代的三个链表(也可能不足三个)进行 merge。最终链接到第 2 代的链表后,一口气执行垃圾回收,打上回收标记。
- 打上不可回收标记。通过有效引用计数,把计数不为「0」的对象打上不可回收标记。
- 把不可回收对象单独存放在一个集合内。并把这些对象中所引用的对象(并且这些引用对象打上了可回收标记),也加入这个集合(双向链表)。
- 对于定义了「
__del__」的对象(finalizer 对象)需要单独用一个 PyListObject 来存放,在删除 finalizer 对象的时候先扣除该对象所引用的对象的引用计数,并清理引用列表,待到引用计数为 0 时再进行垃圾回收,保证回收对象已经不被任何对象引用。 - 三种存储回收对象的链表:
- reachable:保存每次需要回收的所有对象。
- unreachable:保存双向引用的回收对象。
- uncollectable:保存带有「
__del__」函数的双向引用对象。
- 正常情况下的对象会在计数为 0 的时候就被销毁,所以存在于
root object的对象都是双向引用或者被系统引用的对象。后者一般不会被回收。
有效引用计数(解决垃圾回收时环引用):
- 遍历所有需要回收的对象(在 root object 集合中)。根据对象类型,判断每个对象内的引用 是否也是需要回收的对象,如果是,则对他的引用计数「副本」进行「
--」操作,最终引用计数副本为「0」的对象将被视为可能需要回收。
- 遍历所有需要回收的对象(在 root object 集合中)。根据对象类型,判断每个对象内的引用 是否也是需要回收的对象,如果是,则对他的引用计数「副本」进行「
注意事项:
- python 在回收垃圾的时候没办法保证顺序,尽量避免在「
__del__」中引用其他对象。 - python2.7 和 python3.+ 对于执行垃圾回收时,在「
__del__」中引用其他对象这一操作所给出的解决方案有所不同。
- python 在回收垃圾的时候没办法保证顺序,尽量避免在「