本文主要是介绍一些个人开发过程中遇到的奇怪代码,奇怪并非指代代码错误或写法低效,单纯个人知识盲区
# 杂项
# new 运算符和对象初始化
一般调用构造函数的时候,都会初始化对象里的变量,如果不指定的情况下就会执行零构造,对于以下代码,想必大家都很熟悉:
class CMyClass | |
{ | |
int c; | |
} | |
CMyClass a = new CMyClass(); | |
// a.c == 0 |
初始化一个类对象,但其中实际还隐含了一个操作 —— 值初始化。这一步实际上会把 CMyClass 中的成员 c 初始化为 0,并且初始化该类的虚函数表等其他内容,那有什么办法可以只初始化虚函数表等关系,但是不初始化值呢?答案是有的,而且我还撞见了🤔
CMyClass a = new CMyClass(); | |
a.c = 100; | |
/* 如果使用 CMyClass (),则会进行值初始化 */ | |
new (a) CMyClass(); | |
// a.c == 0 | |
/* 如果只是用 CMyClass,则不会进行值初始化,c 依然是 100 */ | |
new (a) CMyClass; | |
// a.c == 100 |
是不是很神奇,但是有一点要注意,这种不进行值初始化的操作,必须避免在无参构造函数内进行值初始化,不然 new (a) CMyClass 依旧会执行无参构造函数内的逻辑,但是否会用初始化值就据取决于构造函数内部的实现了。
# map 的默认插入
例如下面这段代码,在执行 map 的 operate[] 操作的时候,涉及到一个默认值的概念,如果 key 不存在的情况下会构造一个默认的 v,并连同 k 一起插入 map。
这种写法可以简化赋值和初始化的工程,有点类似 python 的 defaultdict :
#include <iostream> | |
#include <map> | |
using namespace std; | |
struct A | |
{ | |
int m; | |
}; | |
int main() | |
{ | |
std::map<int, std::map<int, A>> m_a; | |
m_a[2][1]; // 插入默认的 kv | |
A& a = m_a[1][0]; // 插入默认 kv,并返回 val 的引用 | |
// 直接拿来用... | |
a.m=2; | |
return 0; | |
} |
下面是 operate[] 函数的定义,和原理
mapped_type& | |
operator[](const key_type& __k) | |
{ | |
// concept requirements | |
__glibcxx_function_requires(_DefaultConstructibleConcept<mapped_type>) | |
iterator __i = lower_bound(__k); // 这里查找一个 k >= __k 的位置用来进行插入 | |
// __i->first is greater than or equivalent to __k. | |
if (__i == end() || key_comp()(__k, (*__i).first)) | |
#if __cplusplus >= 201103L | |
__i = _M_t._M_emplace_hint_unique(__i, std::piecewise_construct, | |
std::tuple<const key_type&>(__k), | |
std::tuple<>()); | |
#else | |
__i = insert(__i, value_type(__k, mapped_type())); | |
#endif | |
return (*__i).second; | |
} | |
//_M_emplace_hint_unique 定义 | |
template<typename _Key, typename _Val, typename _KeyOfValue, typename _Compare, typename _Alloc> | |
template<typename... _Args> | |
typename _Rb_tree<_Key, _Val, _KeyOfValue, _Compare, _Alloc>::iterator | |
_Rb_tree<_Key, _Val, _KeyOfValue, _Compare, _Alloc>:: _M_emplace_hint_unique(const_iterator __pos, _Args&&... __args) | |
{ | |
_Link_type __z = _M_create_node(std::forward<_Args>(__args)...); | |
__try | |
{ | |
// 查询合法的插入点 | |
auto __res = _M_get_insert_hint_unique_pos(__pos, _S_key(__z)); | |
// 有合法的插入点,执行插入 | |
if (__res.second) | |
return _M_insert_node(__res.first, __res.second, __z); | |
// 已经存在了,就直接返回 | |
_M_drop_node(__z); | |
return iterator(__res.first); | |
} | |
__catch(...) | |
{ | |
_M_drop_node(__z); | |
__throw_exception_again; | |
} | |
} |
首先我们要知道 C++ map 的实现是基于红黑树,红黑树本身是一棵平衡二叉树,根节点大于左子树小于右子树。
插入的核心 _M_get_insert_hint_unique_pos ,主要功能是查询 key 对应的位置的前节点和后节点,来控制到底是插入在后节点左侧还是右侧:
template<typename _Key, typename _Val, typename _KeyOfValue, typename _Compare, typename _Alloc> | |
pair<typename _Rb_tree<_Key, _Val, _KeyOfValue, _Compare, _Alloc>::_Base_ptr, | |
typename _Rb_tree<_Key, _Val, _KeyOfValue, _Compare, _Alloc>::_Base_ptr> | |
_Rb_tree<_Key, _Val, _KeyOfValue, _Compare, _Alloc>:: _M_get_insert_hint_unique_pos(const_iterator __position, const key_type &__k) | |
{ | |
iterator __pos = __position._M_const_cast(); | |
typedef pair<_Base_ptr, _Base_ptr> _Res; | |
// 等于 _M_end 可以理解为这棵树只有根节点,可能有叶节点 | |
if (__pos._M_node == _M_end()) | |
{ | |
// 有叶节点,并且 key 比最右叶节点还大 | |
if (size() > 0 && _M_impl._M_key_compare(_S_key(_M_rightmost()), __k)) | |
{ | |
// 插入点在 _M_rightmost () 右边 | |
return _Res(0, _M_rightmost()); | |
} | |
else | |
{ | |
// 中间位置做二分查找定位插入点 | |
return _M_get_insert_unique_pos(__k); | |
} | |
} | |
// __k < pos | |
else if (_M_impl._M_key_compare(__k, _S_key(__pos._M_node))) | |
{ | |
iterator __before = __pos; | |
// 如果 pos 已经是最左节点 | |
if (__pos._M_node == _M_leftmost()) | |
{ | |
// 插入点在 _M_leftmost () 左边 | |
return _Res(_M_leftmost(), _M_leftmost()); | |
} | |
// pre_pos < __k < pos | |
else if (_M_impl._M_key_compare(_S_key((--__before)._M_node), __k)) | |
{ | |
//pre_pos 没有右子树 | |
if (_S_right(__before._M_node) == 0) | |
{ | |
// 插入点在 pre_pos 右边 | |
return _Res(0, __before._M_node); | |
} | |
else | |
{ | |
// 插入点在 pos 左边 | |
return _Res(__pos._M_node, __pos._M_node); | |
} | |
} | |
else | |
{ | |
// 中间位置做二分查找定位插入点 | |
return _M_get_insert_unique_pos(__k); | |
} | |
} | |
// pos < k | |
else if (_M_impl._M_key_compare(_S_key(__pos._M_node), __k)) | |
{ | |
iterator __after = __pos; | |
// 如果 pos 已经是最右节点 | |
if (__pos._M_node == _M_rightmost()) | |
{ | |
// 插入点在 pos 的右边 | |
return _Res(0, _M_rightmost()); | |
} | |
// pos < __k < after_pos | |
else if (_M_impl._M_key_compare(__k, _S_key((++__after)._M_node))) | |
{ | |
//pos 没有右子树 | |
if (_S_right(__pos._M_node) == 0) | |
{ | |
// 插入点在 pos 的右边 | |
return _Res(0, __pos._M_node); | |
} | |
else | |
{ | |
// 插入点在 after_pos 的左边 | |
return _Res(__after._M_node, __after._M_node); | |
} | |
} | |
else | |
{ | |
// 中间位置做二分查找定位插入点 | |
return _M_get_insert_unique_pos(__k); | |
} | |
} | |
else | |
{ | |
// 查询到结果直接返回 res.second == 0 表示不插入 | |
return _Res(__pos._M_node, 0); | |
} | |
} |
# piecewise_construct 和 tuple<>()
piecewise_construct 类型主要是用于区分构造函数在构造时,参数混淆的问题。见上面 map 的构造,k 和 v 都可能是一个可变长参数,那么如果传递一个可变长的参数交由 k,v 自己去识别该从哪里开始进行截断,未免太劳烦编译器,因此 piecewise_construct 可以通过后置两个 tuple 的形式来完成参数的隔离,更详细的说明可以参考该文档:

// 对于 map 中 node 的构造 | |
//std::piecewise_construct 用于申明分隔模式 | |
//std::tuple<const key_type&>(__k) 表示构造 k 的参数 | |
//std::tuple<>() 表示构造 v 的参数 | |
_M_t._M_emplace_hint_unique(__i, std::piecewise_construct, std::tuple<const key_type&>(__k), std::tuple<>()); |
那么还有一个问题: tuple<>() 是个什么妖魔鬼怪。下面来看一下它的定义:
// Explicit specialization, zero-element tuple. | |
template<> | |
class tuple<> | |
{ | |
public: | |
void swap(tuple &) noexcept | |
{ /* no-op */ } | |
// We need the default since we're going to define no-op | |
// allocator constructors. | |
tuple() = default; | |
// No-op allocator constructors. | |
template<typename _Alloc> | |
tuple(allocator_arg_t, const _Alloc &) | |
{} | |
template<typename _Alloc> | |
tuple(allocator_arg_t, const _Alloc &, const tuple &) | |
{} | |
}; |
zero-element tuple,顾名思义,一个「空元组」,它是 tuple<T> 的一个特化,这里我猜想应该是为了用无参的默认构造函数来初始化 val,而专门传进去的一个「空元组」来 “凑数” 的~
# C++ 中的 POD
POD 是什么还得从一段 PhysX 代码说起,PhysX 自带的 Array 结构里有一个 popBack 操作,会根据 pop 的内容判断是否调用析构函数:
PX_INLINE T popBack() | |
{ | |
PX_ASSERT(mSize); | |
T t = mData[mSize - 1]; | |
if(!isArrayOfPOD()) | |
{ | |
mData[--mSize].~T(); | |
} | |
else | |
{ | |
--mSize; | |
} | |
return t; | |
} | |
PX_FORCE_INLINE static bool isArrayOfPOD() | |
{ | |
#if PX_LIBCPP | |
return std::is_trivially_copyable<T>::value; | |
#else | |
return std::tr1::is_pod<T>::value; | |
#endif | |
} |
std::tr1::is_pod 便是用来判断一个对象是否为 POD 对象。那么怎么理解什么是 POD 对象呢?

大致就是一个类如果可以用 struct 或者 union 代替,其只有数据定义,没有任何函数时那么就可以称之为一个 POD 对象。
# 稀奇的函数指针声明
函数指针正常的声明方法:
typedef RetType(*FuncName)(Params...) |
这种正常声明比较反人类,变量名和类型参在一起。
另一种有趣的声明方式:
template<typename T> | |
struct Identity{ typedef T FuncType; }; | |
Identity<RetType(*)(Params...)>::FuncType FuncName; // 看着就舒服多了 |
# new 运算符和初始化问题
疑惑代码:
#include <iostream> | |
using namespace std; | |
class A{ | |
friend void* operator new(size_t Size, A& Base); | |
}; | |
inline void* operator new(size_t Size, A& Base){ | |
cout << "new A: " << Size; | |
return NULL; | |
} | |
void Create(){ | |
A a; | |
new (a)B(); | |
}; | |
int main(){ | |
Create(); | |
return 0; | |
} | |
// 无报错版本 | |
class B{}; | |
// ------------ output ------------ | |
new A: 1 | |
// 有报错版本: | |
class B{int bb;}; | |
// ------------ error info ------------ | |
Segmentation fault (core dumped) |
说明:首先 A 类重写了 new 操作符,根据 new 运算符重载规则 new(a)B() 会被解释成 operator new(sizeof(B()), a) :

new 操作符有两个含义:
- 通过给定的对象,计算出需要分配的空间大小,并在 new 运算符内完成内存分配。
- 在分配好的内存地址内执行构造函数来构造对象。
这里 inline void* operator new(size_t Size, A& Base) 的返回值是 NULL,其实代表需要在 NULL 地址处对类 B 进行构造。
上述两个例子的唯一区别在于类 B 是否有成员变量,如果有成员变量的情况下需要对成员变量进行初始化,而初始化需要访问对象内存,因此导致 core dumped
# 扩展
实际上 new 操作在构造函数的时候可以不进行初始化,这个问题上面已经提到过了,就是不添加 () 通过 new(a)B 进行构造。这样也是可行的
void Create() | |
{ | |
A a; | |
new (a)B; | |
}; | |
// ------------ output ------------ | |
new A: 4 |
但是如果类 B 还包含了虚函数表的情况下,这种构造也会有问题,因为虚函数表不管对象是否初始化,都需要创建,就免不了对内存的访问
class B{void virtual p(){};}; | |
// ------------ error info ------------ | |
Segmentation fault (core dumped) |
# 奇怪的拷贝构造和静态函数的临时变量
我们都知道静态函数的临时变量只会在第一次函数执行的时候被初始化:
#include <iostream> | |
using namespace std; | |
class TAlignedBytes | |
{ | |
public: | |
int a; | |
inline TAlignedBytes(){} | |
}; | |
class A | |
{ | |
public: | |
static TAlignedBytes Create() | |
{ | |
TAlignedBytes s; | |
cout << "temp var :" << (void*)&s << " = " << s.a << endl; | |
return s; | |
}; | |
}; | |
int main() | |
{ | |
auto ss = A::Create(); | |
cout << "inst ss:" << (void*)&ss << " = " << ss.a << endl; | |
auto sss = A::Create(); | |
cout << "inst sss:" << (void*)&sss << " = " << sss.a << endl; | |
return 0; | |
} | |
// ------------ output ------------ | |
temp var :0x7fff11504dcc = 0 | |
inst ss:0x7fff11504dec = 0 | |
temp var :0x7fff11504dcc = 32718 | |
inst sss:0x7fff11504de8 = 32718 |
但是如果类 TAlignedBytes 定义了拷贝构造函数的情况下,事情将截然不同,临时变量看起来每次执行都会被初始化,但拷贝构造函数并不会被执行:
#include <iostream> | |
using namespace std; | |
class TAlignedBytes | |
{ | |
public: | |
int a; | |
inline TAlignedBytes(){} | |
inline TAlignedBytes(const TAlignedBytes& Other) | |
{ | |
cout << "copy contructor: " << (void*)this << endl; | |
*this = Other; | |
} | |
}; | |
class A | |
{ | |
public: | |
static TAlignedBytes Create() | |
{ | |
TAlignedBytes s; | |
cout << "temp var :" << (void*)&s << " = " << s.a << endl; | |
return s; | |
}; | |
}; | |
int main() | |
{ | |
auto ss = A::Create(); | |
cout << "inst ss:" << (void*)&ss << " = " << ss.a << endl; | |
auto sss = A::Create(); | |
cout << "inst sss:" << (void*)&sss << " = " << sss.a << endl; | |
return 0; | |
} | |
// ------------ output ------------ | |
temp var :0x7fff18ef1bac = 0 | |
inst ss:0x7fff18ef1bac = 0 | |
temp var :0x7fff18ef1ba8 = 0 | |
inst sss:0x7fff18ef1ba8 = 0 |
然后看了一下汇编代码,发现当存在拷贝构造的时候,静态函数内的临时变量被编译优化了,实际上是用外部传递的 ss 和 sss 作为变量传递给 rdi,再由 rdi 传递给 TAlignedBytes 的构造函数作为 this 指针,析构函数也没有执行:
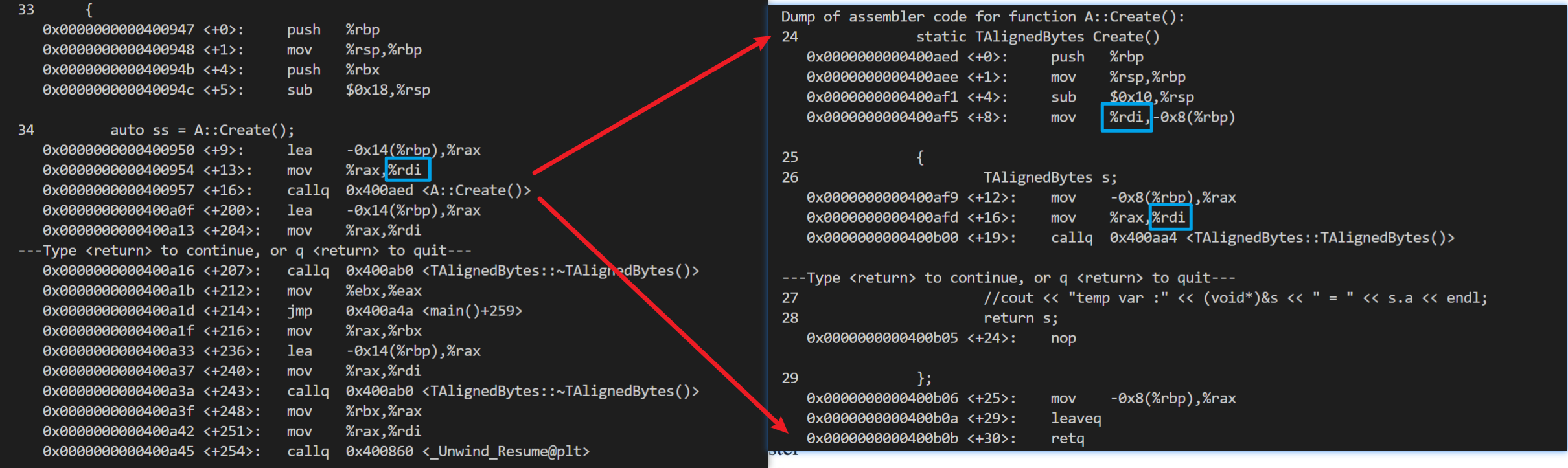
在添加 -fno-elide-constructors 编译指令后,编译临时变量的优化被禁用,因此该特性也被抹除,这时候拷贝构造也被执行:
// ------------ output ------------ | |
temp var :0x7fff0df5392c = 0 | |
copy contructor: 0x7fff0df53958 | |
~TAlignedBytes: 0x7fff0df5392c | |
copy contructor: 0x7fff0df53954 | |
~TAlignedBytes: 0x7fff0df53958 | |
inst ss:0x7fff0df53954 = 0 | |
temp var :0x7fff0df5392c = 32755 | |
copy contructor: 0x7fff0df5395c | |
~TAlignedBytes: 0x7fff0df5392c | |
copy contructor: 0x7fff0df53950 | |
~TAlignedBytes: 0x7fff0df5395c | |
inst sss:0x7fff0df53950 = 32755 | |
~TAlignedBytes: 0x7fff0df53950 | |
~TAlignedBytes: 0x7fff0df53954 |
# 暂时无法解释的现象:
上面都只是创建了两个对象的结果,如果创建更多会怎么样?
// 理论上有构造函数的版本应该每次对象都不一样,且都被重新初始化,但事实并非如此 | |
#include <iostream> | |
using namespace std; | |
class TAlignedBytes | |
{ | |
public: | |
int a; | |
inline TAlignedBytes() { } | |
inline TAlignedBytes(const TAlignedBytes& Other) | |
{ | |
cout << "copy contructor: " << (void *)this << endl; | |
*this = Other; | |
} | |
}; | |
class A | |
{ | |
public: | |
static TAlignedBytes Create() | |
{ | |
TAlignedBytes s; | |
cout << "temp var :" << (void*)&s << " = " << s.a << endl; | |
return s; | |
}; | |
}; | |
int main() | |
{ | |
auto ss = A::Create(); | |
cout << "inst ss:" << (void*)&ss << " = " << ss.a << endl; | |
auto sss = A::Create(); | |
cout << "inst sss:" << (void*)&sss << " = " << sss.a << endl; | |
auto ssss = A::Create(); | |
cout << "inst ssss:" << (void*)&ssss << " = " << ssss.a << endl; | |
auto sssss = A::Create(); | |
cout << "inst sssss:" << (void*)&sssss << " = " << sssss.a << endl; | |
return 0; | |
} | |
// ------------ output ------------ | |
temp var :0x7fff6dfd2acc = 0 | |
inst ss:0x7fff6dfd2acc = 0 | |
temp var :0x7fff6dfd2ac8 = 0 | |
inst sss:0x7fff6dfd2ac8 = 0 | |
temp var :0x7fff6dfd2ac4 = 32767 | |
inst ssss:0x7fff6dfd2ac4 = 32767 | |
temp var :0x7fff6dfd2ac0 = 1845308336 | |
inst sssss:0x7fff6dfd2ac0 = 1845308336 |
无意间在给 TAlignedBytes 添加上析构函数后发现更奇怪的现象,虽然每次都会创建新的对象,但是初始化变成交替进行了:
// ------------ output ------------ | |
temp var :0x7ffcef314b6c = 0 | |
inst ss:0x7ffcef314b6c = 0 | |
temp var :0x7ffcef314b68 = 4196464 | |
inst sss:0x7ffcef314b68 = 4196464 | |
temp var :0x7ffcef314b64 = 0 | |
inst ssss:0x7ffcef314b64 = 0 | |
temp var :0x7ffcef314b60 = 4197520 | |
inst sssss:0x7ffcef314b60 = 4197520 | |
~TAlignedBytes: 0x7ffcef314b60 = 4197520 | |
~TAlignedBytes: 0x7ffcef314b64 = 0 | |
~TAlignedBytes: 0x7ffcef314b68 = 4196464 | |
~TAlignedBytes: 0x7ffcef314b6c = 0 |
# 函数属性声明 __attribute__
// 强制内联,任何情况下都会进行内联,即使编译器关闭了内联优化 | |
inline __attribute__ ((always_inline)) | |
// 强制不内联 | |
__attribute__((noinline)) | |
// 返回值未被使用时,编译会触发 warn | |
__attribute__ ((warn_unused_result)) | |
// 标识函数没有返回值 | |
__attribute__ ((noreturn)) |
# 模板数组应用的声明
template <typename T, size_t SIZE> | |
void print(const T(&array)[SIZE]) | |
{ | |
for (size_t i = 0; i < SIZE; i++) | |
std::cout << array[i] << " "; | |
} |
# enable_if_t 实现模板的类型指定
大概背景是想通过同一个模板调用两个不同的结构体中的相同定义的函数,因此诞下的 hack 产物:
#include <iostream> | |
using namespace std; | |
class A | |
{ | |
public: | |
void P() | |
{ | |
cout << "a" << endl; | |
} | |
}; | |
class B | |
{ | |
public: | |
void P() | |
{ | |
cout << "b" << endl; | |
} | |
}; | |
template <typename T> | |
using require_A_or_B = typename std::enable_if_t<std::is_same<T, A>::value || std::is_same<T, B>::value, int>; | |
template <typename T, require_A_or_B<T> U = 0> | |
class C | |
{ | |
public: | |
void pp(T t); | |
}; | |
template <typename T, require_A_or_B<T> U> | |
void C<T, U>::pp(T t) | |
{ | |
t.P(); | |
} | |
int main() | |
{ | |
A a; | |
C<A> ca; | |
ca.pp(a); | |
B b; | |
C<B> cb; | |
cb.pp(b); | |
return 0; | |
} | |
// --------------------- output --------------------- | |
a | |
b |
唯一比较可惜的事情在于 void C<T, U>::pp(T t) 中对于 t.P(); 的调用,编辑器没办法给出代码提示,因此类似盲打,编码体验比较差。
# decltype && declval
基于上述问题的另一种解决思路就是通过 decltype 来做类型推断,效果会好上不少
#include <iostream> | |
using namespace std; | |
class A | |
{ | |
public: | |
void P() { cout << "a" << endl; } | |
}; | |
class B | |
{ | |
}; | |
template <typename T> | |
class D | |
{ | |
public: | |
auto pp(T t) -> decltype(t.P(), void()); // error: ‘class B’ has no member named ‘P’ | |
}; | |
template <typename T> | |
auto D<T>::pp(T t) -> decltype(t.P(), void()) | |
{ | |
t.P(); | |
} | |
int main() | |
{ | |
A a; | |
B b; | |
D<A> da; | |
da.pp(a); // ok! | |
D<B> db; // error! | |
return 0; | |
} |
declval 可以保证没有构造函数的对象也能够正确被推断,效果是是一样的,后者兼容性更强一些:
template <typename T> | |
class D | |
{ | |
public: | |
auto pp(T t) -> decltype(declval<T&>().P(), void()); | |
}; | |
template <typename T> | |
auto D<T>::pp(T t) -> decltype(declval<T&>().P(), void()) | |
{ | |
t.P(); | |
} |
# requires + concept 来自 c++ 20 的黑科技
话不多说,直接上代码,好用就完事了~
#include <iostream> | |
#include <type_traits> | |
template <typename T> | |
concept HasFuncP = requires(T& t) { t.P(); }; // error! error info: in requirements with 'T& t' [with T = B] | |
class A | |
{ | |
public: void P(){std::cout << "a";} | |
}; | |
class B | |
{ | |
}; | |
class D | |
{ | |
public: | |
static void pp(HasFuncP auto t); | |
}; | |
void D::pp(HasFuncP auto t) | |
{ | |
t.P(); | |
} | |
int main() { | |
A a; | |
D::pp(a); // ok! | |
B b; | |
D::pp(b); // error! error info: no matching function for call to 'D::pp(B&)' | |
return 1; | |
} |
# 模板匹配查询
随便起的名字,具体含义就是通过模板匹配机制来查询模板类中是否包含查询的类型,并返回所对应的下标,代码出自 Unreal5.2 的 TVariantMeta.h :
#include <set> | |
#include <iostream> | |
using namespace std; | |
typedef uint SIZE_T; | |
// 匹配不到情况下的默认结果 | |
template <SIZE_T N, typename LookupType, typename... Ts> | |
struct TParameterPackTypeIndexHelper | |
{ | |
static constexpr SIZE_T Value = (SIZE_T)-1; | |
}; | |
// 匹配成功的结果 | |
template <SIZE_T N, typename T, typename... Ts> | |
struct TParameterPackTypeIndexHelper<N, T, T, Ts...> | |
{ | |
static constexpr SIZE_T Value = N; | |
}; | |
// 匹配不到情况下继续匹配下一个 n+1 | |
template <SIZE_T N, typename LookupType, typename T, typename... Ts> | |
struct TParameterPackTypeIndexHelper<N, LookupType, T, Ts...> | |
{ | |
static constexpr SIZE_T Value = TParameterPackTypeIndexHelper<N + 1, LookupType, Ts...>::Value; | |
}; | |
// 从 Ts 的第 0 个开始匹配 | |
template <typename LookupType, typename... Ts> | |
struct TParameterPackTypeIndex | |
{ | |
static constexpr SIZE_T Value = TParameterPackTypeIndexHelper<0, LookupType, Ts...>::Value; | |
}; | |
int main() { | |
// 这里从模板类中查询 int 类型 <typename LookupType, typename... Ts> | |
std::cout << TParameterPackTypeIndex<int, double, int, double>::Value << "\n"; | |
std::cout << TParameterPackTypeIndex<int, double>::Value << "\n"; | |
return 0; | |
} | |
// ----------------------- output: ----------------------- | |
1 | |
4294967295 |
# 参数包展开
和上面的效果类似,用来比较模板参数包中每个模板类型是否等于 LookupType 类型,并把返回结果保存在 bIsSameType 数组内
template <typename LookupType, typename... Ts> | |
static bool IsSame(SIZE_T TypeIndex) | |
{ | |
static constexpr bool bIsSameType[] = { std::is_same_v<Ts, LookupType>... }; | |
check(TypeIndex < UE_ARRAY_COUNT(bIsSameType)); | |
return bIsSameType[TypeIndex]; | |
} |
# 汉明权重
引自 Unreal 5.2 中 FGenericPlatformMath 部分代码,其中用于计算 BitArray 中有多少位是 1 的实现如下:
static FORCEINLINE int32 CountBits(uint64 Bits) | |
{ | |
// https://en.wikipedia.org/wiki/Hamming_weight | |
Bits -= (Bits >> 1) & 0x5555555555555555ull; | |
Bits = (Bits & 0x3333333333333333ull) + ((Bits >> 2) & 0x3333333333333333ull); | |
Bits = (Bits + (Bits >> 4)) & 0x0f0f0f0f0f0f0f0full; | |
return (Bits * 0x0101010101010101) >> 56; | |
} |
# Union 对数据分段赋值
引自 Unreal 5.2 中 FReplicatedObjectData 部分代码,如何简单划分 uint32 中每一位的作用:
struct FReplicatedObjectData | |
{ | |
union | |
{ | |
uint32 Flags : 32U; | |
struct | |
{ | |
uint32 bShouldPropagateChangedStates : 1U; | |
uint32 bTearOff : 1U; | |
uint32 bDestroySubObjectWithOwner : 1U; | |
uint32 bIsDependentObject : 1U; | |
uint32 bHasDependentObjects : 1U; | |
uint32 bAllowDestroyInstanceFromRemote : 1U; | |
// Padding. Adjust when adding or removing flags. | |
uint32 Padding : 26U; | |
}; | |
}; | |
}; |
这样好处是可以对 Flags 中的任意一位做单独赋值操作,但要注意超过 1U 情况下的赋值会被阶段,取尾段号:
FReplicatedObjectData data; | |
data.bShouldPropagateChangedStates = 1; // 0x01 -> 1 | |
std::cout << data.Flags; // 1 | |
data.bShouldPropagateChangedStates = 2; // 0x10 -> 0 | |
std::cout << data.Flags; // 0 |
# 枚举定义小技巧
经常因为编号问题写起来非常变扭,如果只是希望枚举递增的可以参考下面这种写法:
- 好处是中间插新的会比较方便。
- 不好点就在于具体编号不好计算。
enum class EReplicationInstanceProtocolTraits : uint16 | |
{ | |
None = 0, | |
NeedsPoll = 1, | |
NeedsLegacyCallbacks = NeedsPoll << 1, | |
IsBound = NeedsLegacyCallbacks << 1, | |
NeedsPreSendUpdate = IsBound << 1, | |
NeedsWorldLocationUpdate = NeedsPreSendUpdate << 1, | |
HasPartialPushBasedDirtiness = NeedsWorldLocationUpdate << 1, | |
HasFullPushBasedDirtiness = HasPartialPushBasedDirtiness << 1, | |
HasObjectReference = HasFullPushBasedDirtiness << 1, | |
}; |
# 位操作
# 获取一个数的最低有效位
uint32 AddedSubObjects = ????; | |
const uint32 LeastSignificantBit = AddedSubObjects & uint32(-int32(AddedSubObjects)); | |
// AddedSubObjects = 1(0x1) -> 1 | |
// AddedSubObjects = 2(0x10) -> 2 | |
// AddedSubObjects = 3(0x11) -> 1 | |
// 清理最低有效位 | |
AddedSubObjects ^= LeastSignificantBit; | |
// AddedSubObjects = 1(0x1) -> 0(0x0) | |
// AddedSubObjects = 2(0x10) -> 0(0x0) | |
// AddedSubObjects = 3(0x11) -> 2(0x10) |