以下为个人学习笔记整理。参考书籍《C++ Primer Plus》
# string 类和标准模板库
# string 类
# 构造字符串
string 类的 string::npos 被定义为字符串的最大长度,通常是 unsigned int 的最大值。
通常用 NBTS(null-terminated string)表示空字符结束的字符串 —— 传统的 C 字符串。
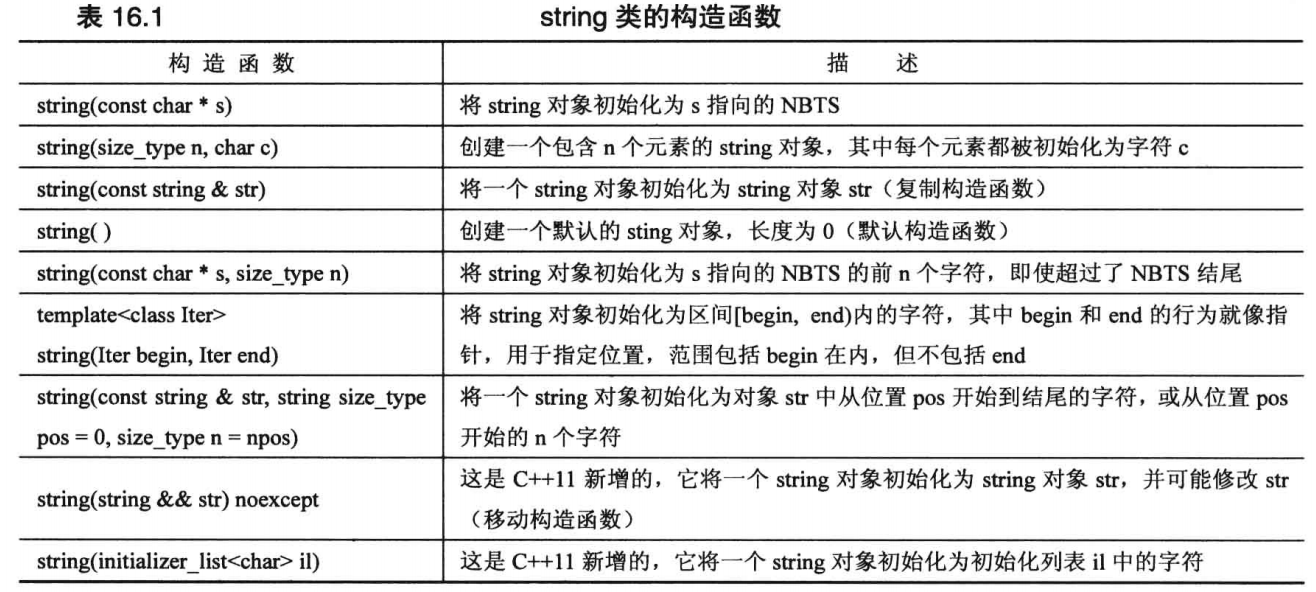
# C++11 新增的构造函数
- 构造函数
string(string&& str)类似于复制构造函数。会为str创建一个新的string副本,但是过程中不能保证str不被修改。这种构造函数被称为移动构造函数(move constructor)。 - 构造函数
string(initializer_list<char> il)让您能够通过初始化列表的方式构建string。string s = {'L','I','S','T'};
# string 类输入
对于 getline() 函数,相比于 C - 风格字符串, string 版本不需要指定对象大小, string 会自动调整到合适大小。另外 C - 风格的 getline() 函数相当于调用 cin 类函数,而 string 版本的则是调用函数把 cin 作为参数:
cin.operator>>(fname); // c-style | |
operator>>(cin, fname); // string |
string 版本的 getline() 函数从输入中读取字符,并存储到 string 对象中,直到发生以下三种情况:
- 到达文件尾,这种情况下,输入流的
eofbit将被设置,这时fail()和eof()返回值将会是true。 - 遇到分界字符(默认为
\n),这种情况下,将把分界字符从输入流中「删除」,但不存储它。 - 读取的字符数量达到了最大允许值 (超过了
string::npos大小或者内存达到上限),这种情况下将设置输入流的failbit,这意味着fail()返回值会是true。
输入流对象有一个跟踪流的错误状态统计
- 检测到文件尾后,将设置
eofbit寄存器 - 检测到输入错误时,将设置
failbit寄存器 - 检测到无法识别的故障(如:硬盘故障)时,将设置
badbit寄存器 - 一切顺利的情况下,将设置
goodbit寄存器
# 使用字符串
string 类的 find 方法重载:

# 智能指针模板类
智能指针相比于普通指针,其中一个区别在于智能指针是一个有着「析构函数」的类对象。可以在指针被销毁的时候,执行一些操作,就比如释放所指对象的内存。从而实现自动回收通过 new 分配来的堆内存。
# 使用智能指针
智能指针模板都定义了类似指针的对象,可以将 new 获得的地址赋给这种对象。并且在智能指针过期时,调用其析构函数来 delete 释放内存。

auto_ptr 的使用:
#include<memory> | |
#include<string> | |
//auto_ptr 包含的构造函数 | |
template<class X> class auto_ptr{ | |
public: | |
explicit auto_ptr(X* p=0) throw(); //explicit 干掉隐式类型转换,避免指针类型转为智能指针 throw () 声明该函数无异常抛出 | |
}; | |
void auto_delete(std::string& s){ | |
std::auto_ptr<std::string> str_p(new std::string(s)); | |
// do something | |
//auto_delete p 所指向的 s 的拷贝字符 | |
return; | |
} |
# 有关智能指针的注意事项
为何摒弃 auto_ptr :
下面这段代码, p_1 和 p_2 都指向了同一块内存地址。这会导致最终该内存地址被释放两次。
auto_ptr<string> p_1(new string("hello world")); | |
auto_ptr<string> p_2; | |
p_2 = p_1; |
要避免这个问题的办法很多:
- 定义赋值运算符,把浅拷贝改为深拷贝。
- 建立所有权(ownership)概念,对于特定的对象,只能有一个智能指针可以拥有它。赋值操作的功能变为转让所有权。这就是
auto_ptr和unique_ptr的策略。但是unique_ptr比auto_ptr更加严格。 - 创建更高智能的指针,跟踪引用特定对象的智能指针数 —— 引用计数(reference counting),仅当引用计数为
0时,才调用delete,这就是shared_ptr的策略。
# unique_ptr 为何优于 auto_ptr
auto_ptr 指针在移交所有权后仍可正常使用,只不过 p_1 指针所指向的内容将不确定,此时如果使用 p_1 将导致不可预测的后果。
// --------------- auto_ptr --------------- | |
auto_ptr<string> p_1(new string("hello world")); | |
auto_ptr<string> p_2; | |
p_2 = p_1; // is ok |
unique_ptr 指针在移交所有权后便不能使用,如果书写如下代码,程序会在编译阶段便失败,把错误早早的扼杀在摇篮。
// --------------- unique_ptr --------------- | |
unique_ptr<string> p_1(new string("hello world")); | |
unique_ptr<string> p_2; | |
p_2 = p_1; // is fail |
# 那么你可能会问:unique_ptr 的赋值还有和意义呢 🤔
unique_str<string> func(const char* s){ | |
unique_ptr<string> temp(new string(s)); | |
return temp; | |
} | |
unique_str<string> p; | |
p = func("hello world"); |
unique_str 可以作为返回值,优于函数内临时创建的 temp 指针在把所有权移交给 p 指针后便会销毁,那么将没有其他地方可以使用 temp 指针。因此这段代码可以正常的运行。
程序试图将一个 unique_ptr 赋给另一个时,如果源 unique_ptr 是一个临时右值,编译器将允许这样做,否则将会被禁止。
如果在万不得已的情况下,非要执行上述禁止的赋值操作时,C++ 提供了一个函数 —— move 。不过执行 move 操作后, p_1 将不能再正常使用。
unique_ptr<string> p_1(new string("hello world")); | |
unique_ptr<string> p_2; | |
p_2 = move(p_1); // is ok |
# unique_ptr 还支持数组形式的内存分配
模板 auto_ptr 只能用于 delete 释放,所以必须和 new 搭配使用。不支持 new[] ,但是 unique_ptr 可以做到这点。
std::unique_ptr<double []>p_d(new double[2]{1.1, 2.2}); // use delete[] |
auto_ptr和share_ptr只支持new分配内存,而unique_ptr则支持new[]和new。
# 选择智能指针
面对上述三种智能指针,在使用上应该如何选择:
share_ptr指针:通常用于需要多个指针指向同一个对象的情况,请使用share_ptr。auto_ptr指针:凡是可以用unique_ptr的地方,都可以使用auto_ptr,不过unique_ptr是更好的选择。unique_ptr指针:当程序不需要或者不允许一个对象被多个指针所指向的情况下,请使用unique_ptr。
share_ptr的赋值支持unique_ptr指针,只要满足unique_ptr的右值规则(临时右值),share_ptr便可接管unique_ptr所指对象。
# 标准模板库
STL 提供了一组表示容器、迭代器、函数对象和算法的模板。
- 容器:一个和数组类似的存储单元。
- 算法:特定的内置函数,如排序,查找等。
- 迭代器:用于遍历容器对象。
- 函数对象:类似于函数的对象,可以是类对象或函数指针。
# 模板类 vector
定义 vector 对象:
#include<vector> | |
std::vector<int> v{1,2,3,4,5}; |
# 其他 vector 操作
size():返回容器内元素数目。swap():交换两个容器内容。begin():返回指向容器内第一个元素的迭代器。end():返回一个表示超过容器尾的迭代器。push_back():在容器末尾添加新元素,如果超过了容量,则会自动扩容。v.push_back(1);erase():删除给定区间内的元素,接受两个迭代器,一个开始,一个结束。v.erase(v.begin()+1, v.begin()+3);insert():插入元素,接受三个迭代器,一个表示插入位置,后两个表示插入的区间内容。v.insert(v.begin(), new_v.begin, new_v.end());find():查找容器元素。for_each():接受三个参数,前两个迭代器定义区间,最后一个参数指定执行函数(函数指针)
for(vi = v.begin(); vi != v.end(); vi++) //#1 | |
func(*vi); | |
for_each(v.begin(), vi.end(), func) // same as #1 |
random_shuffle():打乱容器元素。接受两个迭代器参数用于表示区间。random_shuffle(vi.begin(), vi.end());sort():对容器元素排序。接受两个迭代器参数用于表示区间,一个可选参数(比较器函数)用于自定义排序规则
sort(vi.begin(), vi.end()); // 默认情况下将使用操作运算符 operator<() | |
sort(vi.begin(), vi.end(), comparer_func); // 带比较器的 sort | |
bool comparer_func(const type& a, const type& b){ | |
// ... | |
} |
rbegin():返回一个指向超尾的反向迭代器。rend():返回一个指向第一个元素的反向迭代器。
// 把 v 容器内的对象,反向拷贝到 new_v 容器内 | |
copy(v.rbegin(), v.rend(), new_v.begin()); |
# 迭代器 Iterator
用于迭代容器的对象,一个广义上的指针,为各种操作符提供重载并且定义合理的迭代对象规则,以 vector 模板为例:
vector<double>::iterator vi; // a vector<double> iterator | |
vector<double> v; | |
vi = v.begin(); | |
*vi = 1.1; // 给 vector 容器的第一个元素赋值为 1.1 | |
++vi; // 迭代器指向容器的下一个元素 |
另外 C++11 自动类型推断还为迭代器的定义提供了更加简洁的定义:
vector<double>::iterator vi = v.begin(); // #1 | |
auto vi = v.begin(); // same #1, C++11 automatic type deduction |
# 什么是超过容器尾的迭代器?
迭代器从容器的第一个元素,依次遍历整个容器,最终到达容器最后一个元素之后的位置称为「超过容器尾」。一般用于表示迭代器迭代整个容器结束:
for(vi = v.begin(); vi != v.end(); vi++) | |
std::cout << *vi << endl; |
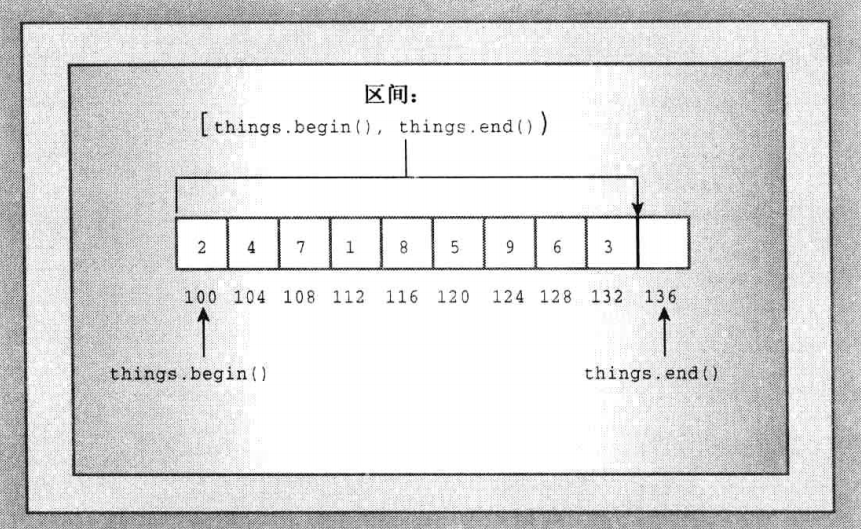
# 分配器 Allocator
各种 STL 容器模板都接受一个可选的模板参数,该参数指定使用哪个分配器对象来管理内存,以 vector 模板为例:
template<class T, class Allocator = allocator<T> > | |
class vector{ | |
// ... | |
}; |
如果没有指定 Allocator,那么容器模板将使用默认分配器 —— allocator<T> 。这个类使用 new 和 delete 来管理内存。
# 基于范围的 for 循环(C++11)
double ds[5] = {1.1, 2.2, 3.3, 4.4, 5.5}; | |
// 简单版本,指定类型 | |
for(double x: ds) | |
std::cout << x << endl; | |
// 类型推断通用版本 | |
for (auto x: ds) | |
std::cout << x << endl; | |
// 支持修改值的类型推断通用版本 | |
for (auto& x: ds) | |
std::cout << x << endl; |
# 泛型编程
# 为何使用迭代器
迭代器可以把不同对象的迭代规则抽象出来,汇总为一个统一的接口。这样的好处就是能够适配任何容器。
例如针对数组和链表的迭代操作,如果要书写一个通用的 find 函数,它们逻辑完全相同,只是迭代规则不同,这时如果把迭代抽象出来,将可以得到一个统一接口。
//double 数组的 find 操作 | |
double* find_double(double* lst, int n, const double& val){ | |
for(int i = 0; i < n; i++) | |
if (lst[i] == val) | |
return &lst[i]; | |
return 0; | |
} | |
// 链表的 find 操作 | |
Node* find_Node(Node* head, double& val){ | |
Node* start; | |
for(start = head; start !=0; start=start->next) | |
if(start->value == val) | |
return start; | |
return 0; | |
} | |
//iterator 版本 | |
iterator find_any(iterator lst, int n, const double& val){ | |
for(int i=0; i<n; i++, lst++) | |
if(*lst == val) | |
return lst; | |
return 0; | |
} |
# 迭代器类型
通过实现不同的函数接口可以使得迭代器具备不同的功能:
- 实现 ++ 运算符,可以让迭代器顺序遍历容器
- 实现 + 操作可以让迭代器随机访问成员
- 定义 * 运算符可以让迭代器能够访问成员数据
- ....
为此 STL 定义了五种迭代器:
- 输入迭代器
- 输出迭代器
- 正向迭代器
- 双向迭代器
- 随机访问迭代器
对于上述的 5 种迭代器,都可以执行解除引用操作( * ),也可以进行比较操作( == / != )。
如果两个迭代器相等,将意味着,他们解除引用所获得的值也相同:
iter1 == iter2 | |
*iter1 == *iter2 |
# 输入迭代器
输入迭代器被定义为用来读取数据,因此不具备修改数据的功能。且必须能够访问容器所有元素。
此外输入迭代器被处理为「单通行(single-pass)」:
- 迭代第二遍的结果不能保证和第一次一致。
- 不依赖前一次的迭代器值,也不依赖本次迭代中前面的迭代值。
- 迭代器只能是单向递增,不能倒退。
# 输出迭代器
输出迭代器被定义为向容器内赋值。和输入迭代器类似,输出迭代器也是「单通行(single-pass)」,区别在于:一个只读,一个只写。
# 正向迭代器
和输入输出迭代器类似,正向迭代器也使用 ++ 来遍历容器,唯一的区别在于正向迭代器支持多次迭代,且同时具备读写功能。
# 双向迭代器
双向迭代器具备正向迭代器的全部功能,同时支持双向迭代(递增,递减)。
# 随机访问迭代器
某些操作需要随机访问迭代容器,此时便可使用随机访问迭代器。其具备双向迭代器的所有特性,还支持 +/- 运算和索引操作等。
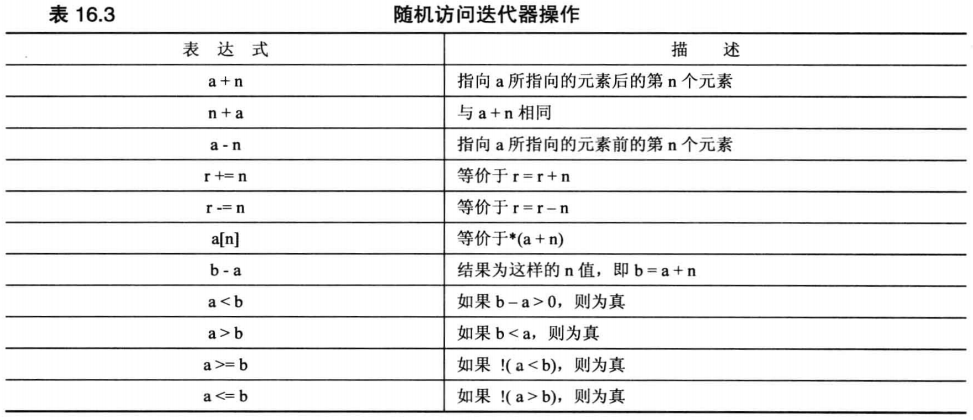
# 迭代器层次结构
# 概念、改进和模型
迭代器本身不是特定的一个对象或者类,而是一个规则。换句话说,只要实现了这些规则的对象都可以被称为迭代器。
因此指针也是一个迭代器,因为其满足了迭代器的要求:
# 指针用作迭代器
double d_ar[10]; | |
sort(d_ar, d_ar+10); // 把指针当作迭代器参数传递 | |
vector<double> v[10]; | |
copy(d_ar, d_ar+10, v.begin()); // 把 arr 里的数据拷贝到 vector 内 |
# ostream_iterator 和 istream_iterator 模板
#include<iterator> | |
// 声明一个输入迭代器,接受 int 类型的数据,并转化为 char 类型, std::cout 指出所使用的输入流, 最后一个参数表示分隔符。 | |
ostream_iterator<int, char> out_iter(std::cout, "|"); | |
*out_iter++ = 123; // work like std::cout << 123 << "|"; | |
vector<int> v{1,2,3,4,5}; | |
copy(v.begin(), v.end(), out_iter); // 打印 vector 的每个元素,中间用 | 符隔开。 result 1|2|3|4|5 | |
// 声明一个输出迭代器,接受 char 类型数据,转化为 char 类型,并把结果存储在 std::cin 内。 | |
istream_iterator<char, char> in_iter(std::cin); | |
while (*in_iter != '0') { | |
std::cout << *in_iter << std::endl; | |
in_iter++; | |
} |
# 插入迭代器
STL 提供了三种插入迭代器: back_insert_iterator 、 front_insert_iterator 和 insert_iterator 。
- back_insert_iterator:将元素插入到容器尾部。
back_insert_iterator<vector<int> > back_iter(v); - front_insert_iterator:将元素插入到容器头部。
front_insert_iterator<vector<int> > front_iter(v); - insert_iterator:将元素插入到指定位置。
insert_iterator<vector<int> > insert_iter(v, v.begin());
不同的插入迭代器适用于不容的容器,因为他需要依赖容器的接口实现,例如 back_insert_iterator 可用于 vector ,其默认容器实现了 push_back 方法。
# 容器种类
容器是用于存储对象的结构的统称。常见的容器有如下几种:
- deque
- list
- queue
- priority_queue
- stack
- vector
- map
- multimap
- set
- multiset
- biset
- forward_list
- unordered_map
- unordered_multimap
- unordered_set
- unordered_multiset
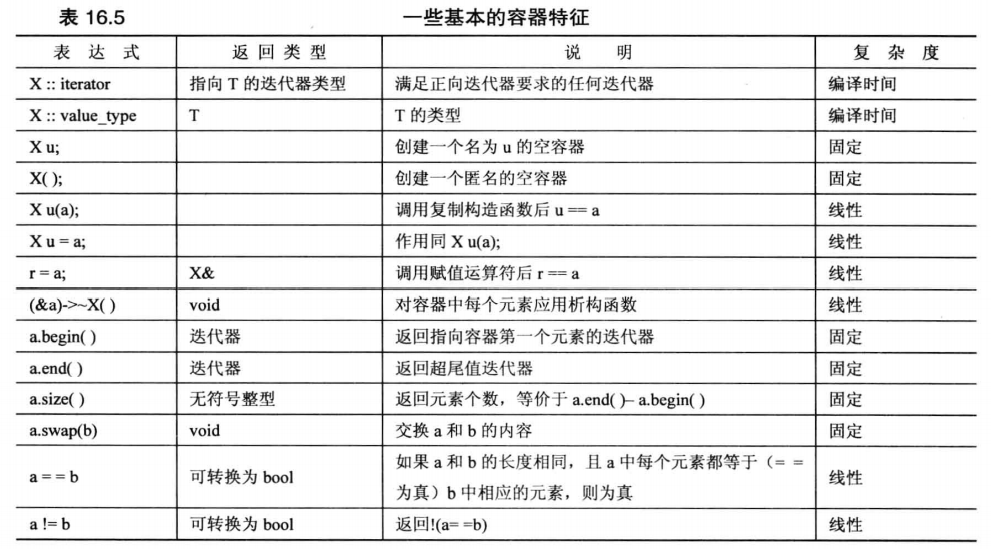
以上三种的所需时间由快到慢依次为:「编译时间」>「固定时间」>「线性时间」
- 编译时间:编译时完成,运行消耗忽略不计。
- 固定时间:运行所需时间和容器元素数量无关。
- 线性时间:运行所需时间和元素数量成正比。
# C++11 新增的基本容器要求
X::iterator 满足正向迭代器要求。

# 序列
序列要求满足如下几个性质:
- 能够正向迭代。
- 元素按照特定顺序排列,不会因为迭代过后发生变化。
- 排列方式必须为线性且必须有第一个和最后一个元素。每个元素前后都必须有元素。
常见的序列容器有以下 7 种:
- duque:双向队列
- forward_list(C++11):单向链表
- list:双向链表
- queue:单向队列
- priority_queue:优先队列
- stack:栈
- vector:可变长数组
- array(C++11):固定长数组
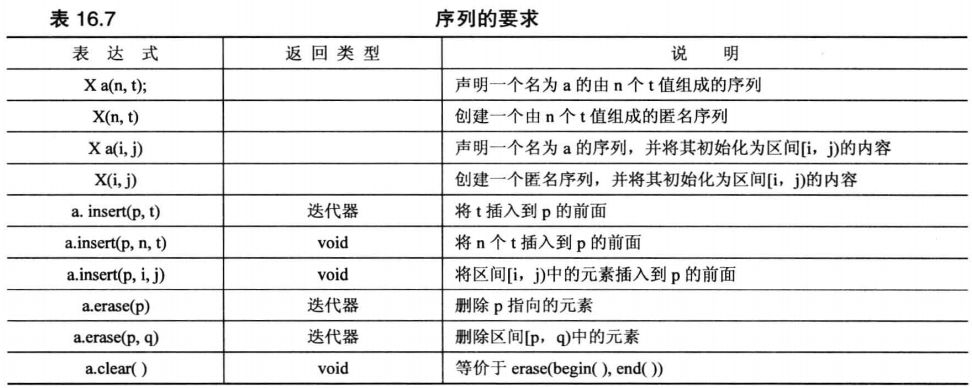
下图表示序列需要支持的操作,其中 t 表示类型为 T 的存储在容器内的元素值, n 表示整数, p 、 q 、 i 和 j 表示迭代器。
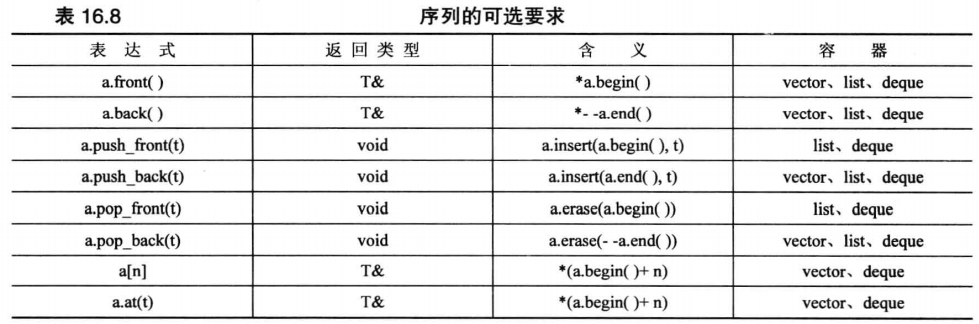
如下表示序列能够支持的可选运算符操作,并且操作复杂度为固定时间:
# vector
一种动态数组,可以动态扩容和缩容,提供元素的随机访问,能够方便的在尾部进行操作,并且支持反向迭代。
# deque
双端队列,支持随机访问,在首部和尾部的操作都比较方便。
# list
双向链表,支持双向遍历,相比于 deque ,能够很好的支持在除首尾的其他位置进行插入和删除。支持反向迭代,但不提供随机访问。
此外,STL 还提供了一些只有链表才支持的操作:

splice 和 insert 都是插入操作,但是 splice 更类似于剪切粘贴,而 insert 则是复制粘贴。
# forward_list(C++11)
单向链表,提供正向迭代。功能比较简单。
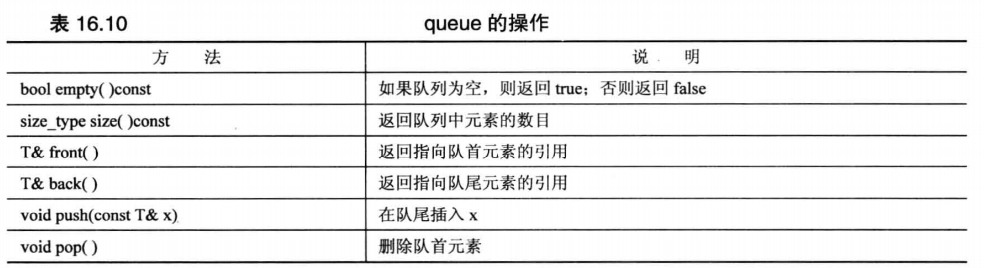
# queue
单向队列,不允许随机访问元素,不允许遍历队列,只能将元素加入队尾,从队首取出元素和查看首尾元素,查看元素数量和判断队空。
# priority_queue
优先队列,底层实现是 vector ,支持随机访问,支持 queue 的所有操作,且保证了最大元素始终置于队首。可以自定义比较器(在构造队列时设置)。
# stack
和 queue 类似,底层实现时 vector ,不支持随机访问,不允许遍历,支持把元素放入栈顶和从栈顶取出元素
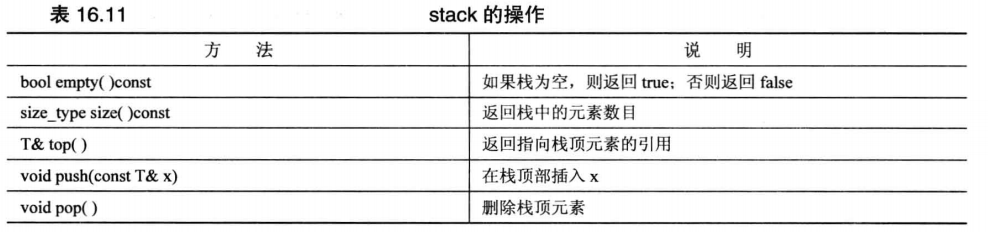
# array(C++11)
固定长度的数组,其他操作和 vector 类似,但不支持修改容器大小的操作,例如: push_back、insert 。
# 关联容器
按照 k-v 形式存储的容器。关联容器本质上都是基于树结构构建的,且都是有序的,STL 提供了 4 种关联容器:
- set:定义在
set.h - multiset:定义在
multiset.h - map:定义在
map.h - multimap:定义在
multimap.h
# set
集合,底层实现通常是红黑树,可反转、排序,且键(键就是值)是唯一的,不存储多个相同的值
STL 还支持部分集合的操作函数:
set_union并集操作
#include <set> | |
#include <algorithm> | |
std::set<int> s{ 1,2,3,7 }; | |
std::set<int> ss{ 1,2,3,5 }; | |
std::set<int> sss; | |
std::set_union(ss.begin(), ss.end(), s.begin(), s.end(), std::insert_iterator<std::set<int> >(sss, sss.begin())); | |
std::ostream_iterator<int, char> out_iter(std::cout, "|"); | |
std::copy(sss.begin(), sss.end(), out_iter); | |
// output: 1|2|3|5|7| |
set_intersection交集操作
#include <set> | |
#include <algorithm> | |
std::set<int> s{ 1,2,3,7 }; | |
std::set<int> ss{ 1,2,3,5 }; | |
std::set<int> sss; | |
std::set_intersection(ss.begin(), ss.end(), s.begin(), s.end(), std::insert_iterator<std::set<int> >(sss, sss.begin())); | |
std::ostream_iterator<int, char> out_iter(std::cout, "|"); | |
std::copy(sss.begin(), sss.end(), out_iter); | |
// output: 1|2|3| |
set_difference差集操作
#include <set> | |
#include <algorithm> | |
std::set<int> s{ 1,2,3,7 }; | |
std::set<int> ss{ 1,2,3,5 }; | |
std::set<int> sss; | |
std::set_difference(ss.begin(), ss.end(), s.begin(), s.end(), std::insert_iterator<std::set<int> >(sss, sss.begin())); | |
std::ostream_iterator<int, char> out_iter(std::cout, "|"); | |
std::copy(sss.begin(), sss.end(), out_iter); | |
// output: 5| |
lower_bound:返回一个迭代器,指向集合中第一个不小于参数的对象。
std::set<int> ss{ 1,2,3,5 }; | |
std::set<int>::iterator is = ss.lower_bound(4); | |
std::cout << *is <<std::endl; | |
// output: 5 |
upper_bound:返回一个迭代器,指向集合中第一个大于参数的对象。
std::set<int> ss{ 1,2,3,5 }; | |
std::set<int>::iterator is = ss.upper_bound(4); | |
std::cout << *is <<std::endl; | |
// output: 5 |
# multiset
和 set 类似,底层实现通常也是红黑树,支持相同键。
std::multiset<int> ms{ 1,3,2,2,1 }; | |
std::ostream_iterator<int, char> out_iter(std::cout, "|"); | |
std::copy(ms.begin(), ms.end(), out_iter); | |
// output: 1|1|2|2|3| |
# map
底层实现是平衡二叉树,不允许相同的键,但支持相同的值。
#include<map> | |
std::map<int, std::string> mp { | |
{1,"1",}, | |
{1,"string",}, | |
}; | |
std::cout << mp[1] << std::endl; | |
// output: 1 |
# multimap
底层实现是平衡二叉树,允许相同的键。有一点需要注意 multimap 不支持 [] 运算符。
std::multimap<int, std::string> mmp{ | |
{1,"1",}, | |
{1,"string",}, | |
}; | |
for (auto iter = mmp.begin(); iter != mmp.end(); iter++) { | |
std::cout << "key:" <<iter->first << ", val:" << iter->second << std::endl; | |
} | |
// output: | |
key:1, val:1 | |
key:1, val:string |
# 无序关联容器
相比于关联容器,无序关联容器是基于哈希表实现的,这种方式可以提高操作效率,但是没办法保证容器内元素的次序。STL 提供了以下四种无序关联容器:
- unordered_set
- unordered_multiset
- unordered_map
- unordered_multimap
# 函数对象
大部分 STL 算法都使用函数对象 —— 函数符(functor)。函数符是可以以函数方式与 () 结合使用的任意对象。包括函数名和重载了 () 运算符的类对象。
# 函数符概念
- 生成器(generator):不需要参数就可以直接调用的函数符。
- 一元函数(unary function):一个参数的函数符。
- 二元函数(binary function):两个参数的函数符。
- 返回值为
bool类型的一元函数是谓词(predicate) - 返回值为
bool类型的二元函数是二元谓词(binary predicate)
# 预定义的函数符
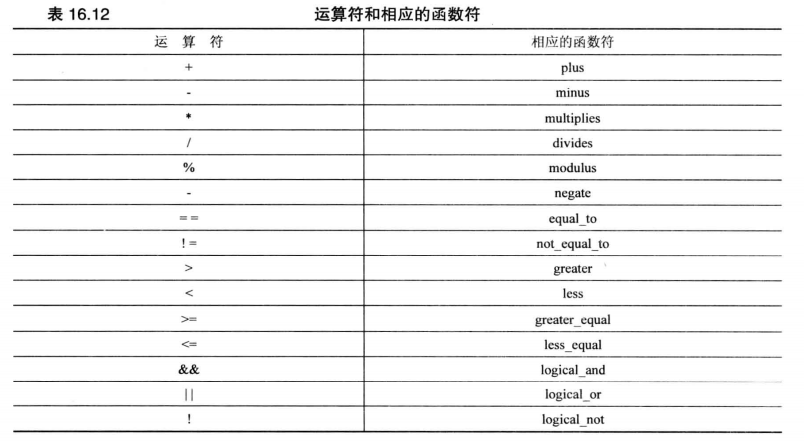
functional 包内提供了以下这种函数符:
#include<functional> | |
std::plus<double> add_double; // define add_func | |
std::cout << add_double(1.1, 2.2); // use add_func |
# 自适应函数符和函数适配器
上述表格种的函数都是自适应的。STL 定义了五种自适应函数符:
- 自适应生成器(adaptable genertaor)
- 自适应一元函数(adaptable unary function)
- 自适应二元函数(adaptable binary function)
- 自适应谓词(adaptable predicate)
- 自适应二元谓词(adaptable binary predicate)
自适应的意义在于定义了 typedef 成员,可以通过 func<typeName> 的形式定义函数符。
此外,STL 还支持对函数操作符的包装( binder1st 、 binder2nd ):
#include<functional> | |
std::plus<double> add_double; | |
auto add_point_1 = std::bind1st(add_double, 1.1); // same as add_point_1 = add_double(1.1, x) | |
auto add_point_2 = std::bind2nd(add_double, 2.2); // same as add_point_2 = add_double(x, 2.2) | |
std::cout << add_double(1.1, 2.2); // 1.1 + 2.2 = 3.3 | |
std::cout << add_point_1(2.2); // 2.2 + 1.1 = 3.3 | |
std::cout << add_point_2(1.1); // 1.1 + 2.2 = 3.3 |
# 算法
STL 将常见算法分成 4 组,封装在 #include <algorithm> 库中:
- 非修改式序列操作;
- 修改式序列操作;
- 排序和相关操作;
- 通用数字运算。
# 函数和类函数
通常情况下建议使用 STL 提供的类函数而非函数,虽然两种功能类似,但类函数可以针对不同类型进行定制化操作,例如增缩容等。
# 其他库
# vector、valarray、array 数组模板
vector 模板类是一个容器类和算法系统的一部分。支持面向容器的操作,如排序、插入、重新排列、搜索、将数据转移到其他容器。
valarray 类模板是面向数值计算的,不属于 STL 的一部分。重载了较多的运算符,为数学运算提供了简单直观的接口,效率来说不是最好的。
array 表示固定的数组,由于该特性,其执行效率比强两个更快。
# 模板 initializer_list(C++11)
改模板支持通过初始化列表的形式对容器元素进行初始化操作。能支持该操作是因为容器的构造函数中有一个 initializer_list<T> 作为参数的版本。
// 两者等效 | |
std::vector<double> v_d({1.1, 2.2, 3.3, 4.4, 5.5}); | |
std::vector<double> v_d {1.1, 2.2, 3.3, 4.4, 5.5}; |
# 使用 initializer_list
#include <initializer_list> | |
std::initializer_list<double> dl = { 1.1, 2.2, 3.3, 4.4 }; | |
for (auto i = dl.begin(); i != dl.end(); i++) { | |
std::cout << *i << std::endl; | |
} |