以下为个人学习笔记整理。参考书籍《C++ Primer Plus》
# 十七、输入、输出和文件
# C++ 输入和输出概述
# 流和缓冲区
在流的「搬运」工程中,程序本身起到了流缓冲的作用。而输入和输出则可以是任意的文件、程序、设备等。
- 将流与输入去向的程序关联起来。
- 将流与输出去向的程序关联起来。

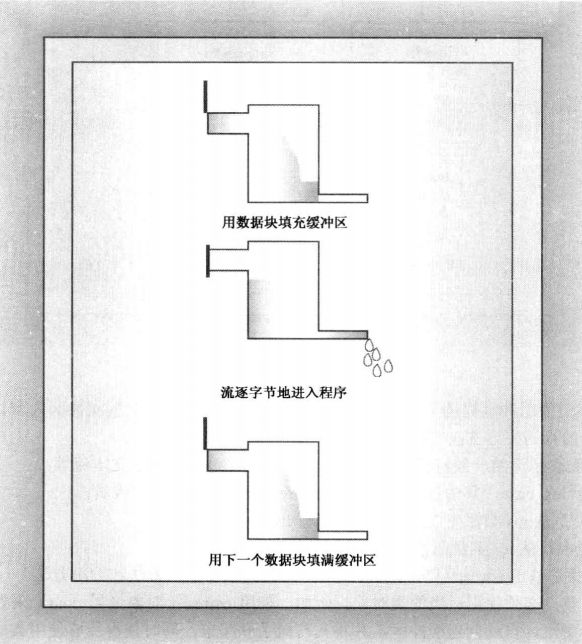
相比于每次读取一个字符再进行处理,一口气读取大量数据,在进行批量处理不失为一种高效的方式。缓冲区可以高效的批量处理数据,就像一个蓄水池。
由此缓冲区便横空出世了。程序每次从输入方获取大量数据到缓冲区,并通过刷新缓冲区的方式批量写入到输入方,之后清空缓冲区。
这种方式也被称为 ——「刷新缓冲区」
# 流、缓冲区和 iostream 文件
管理流和缓冲区往往是一件细致且琐碎的工作,为此 iostream 文件提供了一套专门的实现,用于管理流和缓冲区。
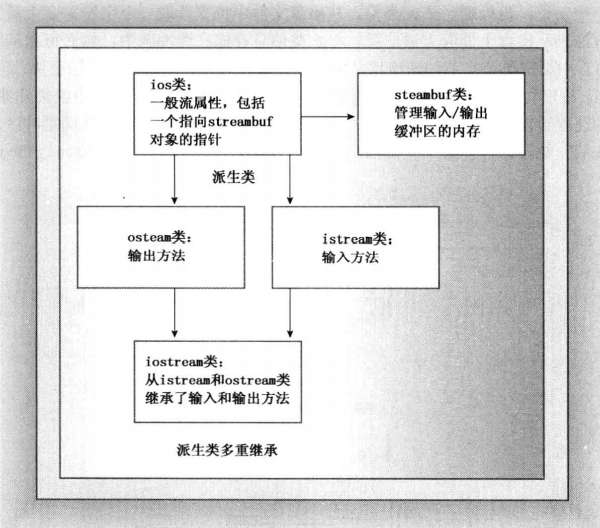
- streambuf 类为缓冲区提供了内存,并提供了用于填充缓冲区、访问缓冲区内容、刷新缓冲区和管理缓冲区内存的类方法;
- ios_base 类表示流的一般特征,如是否可读取,是二进制还是文本格式。
- ios 类基于 ios_base ,其中包括了一个指向 streambuf 对象的指针成员。
- ostream 类从 ios 派生而来,提供了输出方法。
- istream 类从 ios 派生而来,提供了输入方法。
- iostream 基于 ostream 和 istream 类的,提供了输入和输出方法。
# I/O 那些事
为支持国际通用语言, C++ 必须能够支持 16 位的国际字符集。为此,在传统的 8 位 char「窄」类型基础上,增加了 char16_t 和 char32_t 。因此为了代码复用,制定了一套 I/O 的类模板用于适配。除此之外,还为每个类型提供了一套具体化的类型:
- istream 和 ostream 是 char 的具体化。
- wistream 和 wostream 是 wchar_t 的具体化。
- wcout 对象用于输出宽字符流,等等诸如此类的设计。
- cin 对象用于标准输入流。默认情况下被关联到标准输入设备(通常是键盘),wcin 和 cin 类似,但处理的是 wchar_t 类型。
- cout 对象用于标准输出流。默认情况下被关联到标准输出设备(通常是显示器)。wcout 和 cout 类似,但处理的是 wchar_t 类型。
- cerr 对象与标准错误流相对应,可用于显示错误信息。默认情况下被关联到标准输出设备(通常是显示器)。这个流没有被缓冲。因此刷新上会比较及时。wcerr 和 cerr 比较类似,但处理的是 wchar_t 类型。
- clog 对象也对应着标准错误流。区别在于这个流会被缓冲,wclog 类似,但处理的是 wchar_t 类型。
# 重定向
用来修改标准输入和标准输出的源头。
通常情况下,我们会把一些需要从键盘上获取的输入流重定向为从文件中获取,或者需要输出到显示器的输出流重定向到文件内保存。
# 使用 cout 进行输出
C++ 将输出视作字节流(由于各个平台规范不同,字节的大小可能是 8 位、16 位、32 位等)。而在程序中,数据往往会组织成比字节更大的单位。例如 int 类型可能是 16 位也可能是 32 位。double 则是 64 位。但在字节流发送给屏幕时,希望每个字节表示一个字符值。
例如:1.2 是由 1 、 . 、 2 三个字符所组成的,为此 ostream 需要把 1.2 的 float 类型转化为以文本形式表示的字符流。
# 重载的 << 运算符
<< 运算符原本的含义是移位操作,但针对 ostream 类进行了一系列的重载,使其可以用于所有基本类型的输出。
此外 ostream 类还为下面的指针类型定义了插入运算符:
- const signed char *
- const unsigned char *
- const char *
- void *
因此在处理上述指针对象的时候, << 也将被视作输入运算符。
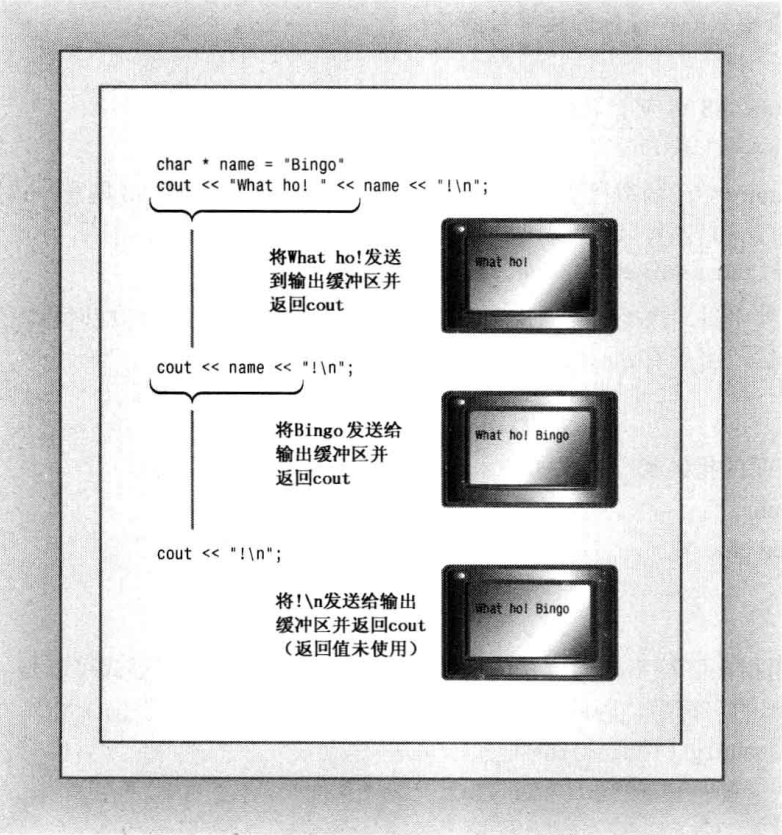
# 拼接输出
由于 ostream 的 << 运算符返回值类型是 ostream & 。所以可以使用多个 << 运算符实现「拼接输出」的效果:
cout << "A" << "B" << "C"; |
# 刷新输出缓冲区
如果不希望等到缓冲区被填满后才真正输出到显示设备上,可以向缓冲区内加入回车字符。当接受到回车字符时,将会引发缓冲区刷新,从而及时将结果输出到显示设备上。本质上,该刷新操作调用了 cout 对象的 flush 函数。
# 用 cout 进行格式化
- 对于 char 值,如果他代表可打印的字符,则将作为一个字符显示在一个字符宽度的字段中。
- 对于整型,将以十进制的方式显示在一个刚好容纳该数字及负号的字段中。
- 字符串被显示在宽度等于该字符串长度的字段中。
- 浮点数字本身是按照科学计数还是定点表示法取决于数值本身的值。字段宽度可以刚好容纳数字和负号。新式和老式存在一些区别:
- 新式:被显示成 6 位,末尾的 0 不显示。默认行为对应于带 % g 说明符的标准 C 库函数
fprinrf() - 老式:浮点类型显示为带 6 位小数,末尾的 0 不显示。
- 新式:被显示成 6 位,末尾的 0 不显示。默认行为对应于带 % g 说明符的标准 C 库函数
# 调整输出格式
如果想要输出的整型显示为 16 进制,可以使用如下方式:
cout << hex<< 10; |
# 调试字段宽度
通常我们希望输出的内容尽量的对齐,这意味着每个输出的宽度是一致的,可以通过如下方式实现:
cout.width(2); // 设置宽度为 2 | |
cout << 1; |
通过 width 的方式修改宽度只会生效一次,只会再次输出时,宽度会回到默认值。
如果设置的宽度小于显示所需的最小宽度,那么设置将会失效,C++ 优先考虑显示完整,再考虑整齐问题。
# 填充字符
默认情况下 C++ 使用空格来填充未被使用的部分,但也可以通过 fill 自定义填充内容:
cout.fill("*") | |
cout.width(2); | |
cout << 1; | |
// ----------- output:1* |
# 设置浮点数精度
可以通过 precision 函数设置浮点数的精度显示
cout.precision(4); | |
cout << 20; | |
// ----------- output:20.00 |
# 打印末尾的 0 和小数点
有些时候,保留末尾小数会让显示看起来更美观,可以使用 ios_base::showpoint 来实现:
cout.setf(ios_base::showpoint); | |
cout.precision(2); | |
cout << 20; | |
// ----------- output:20. |
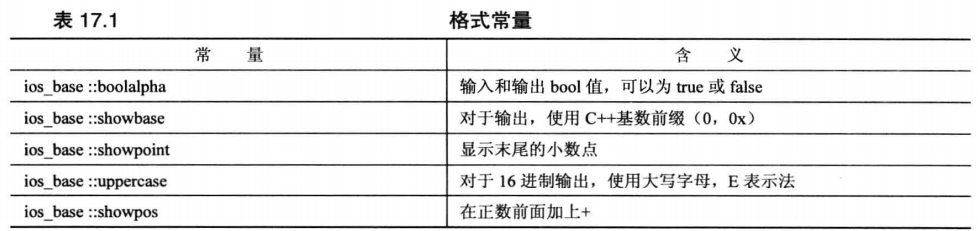
# setf 的第一个原型需要传递一个参数,用于控制各项功能,其配置如下:
# setf 的另一个原型还接受一个额外的参数,第二个参数用于在第一个参数的基础上在做一定的限制,配置如下:
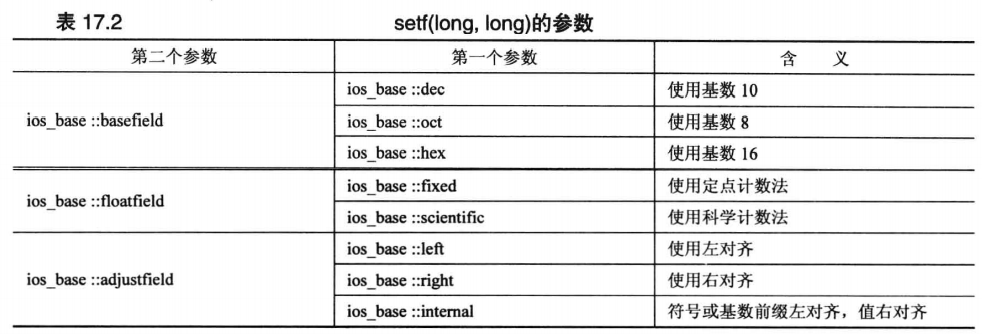
上述的设置显然还是过于复杂,为此 C++ 提供了一些常用的配置组合,程序只需信手拈来即可:

# 使用 cin 进行输入
默认情况下,cin 通过读取键盘的输入流,并根据输入格式,将字符序列转化为所需的类型。
# 重载的 >> 运算符
和 cout 类似, cin 同样也重载了运算符,并且支持了所有的基础类型引用作为参数。以及一些特定的指针:
- signed char *
- char *
- unsigned char *
并且 cin 也支持拼接输入:
char name[20]; | |
float fee; | |
int group; | |
cin >> name >> fee >> group; |
# cin >> 是如何检查输入
C++ 输入操作会跳过空白(包括:空格、换行、制表符),直到遇到非空白字符。
在单字符模式下:运算符将读取该字符并放置到特定位置(空白字符除外)。
在其他模式下:运算符将读取一个指定类型的数据。读取从非空白字符开始,到遇到第一个不匹配的字符结束的中间内容。
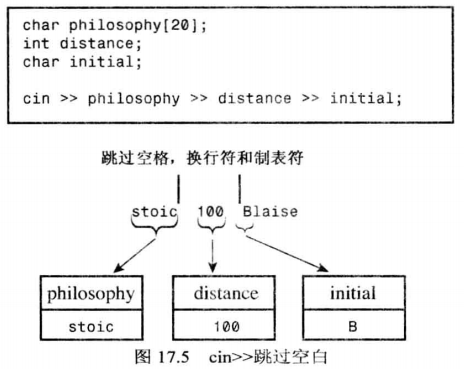
假设需要读取一个整型,从键盘上输入 -123A 那么在读取到 A 的时候,将把 -123 赋值给该整型,并且停留在 A 的位置等待下一个需要读取的对象。
假设第一个读取的输入就不满足整型的要求,那么将会返回 0 并且提升读取状态为 false 。
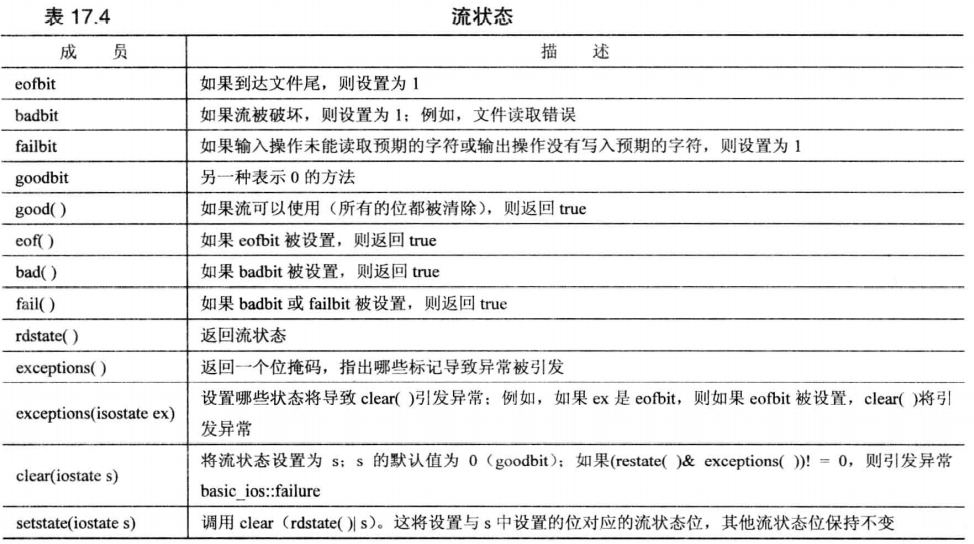
# 流状态
流状态由三个元素组成: eofbit 、 badbit 、 failbat 。其中每个元素代表一位。如果三个位上都是 0 ,那么本次读取是成功的。
# 设置状态
设置状态提供了两种方法 ——clear () 和 setstate ()。
- clear:用于清除状态并且设置某个状态,当传入设置参数的时候其等效于
clear() && setstate(state)。clear(); clear(eofbit)。 - setstate:只能用于设置某个状态。
setstate(eofbit)。
# I/O 和异常
通过 exceptions() 可以控制不同情况下是否抛出异常:
cin.exceptions(badbit); // 设置当 cin 输入发生 badbit 时,将引发异常 | |
cin.exceptions(badbit|eofbit); // 设置当 cin 输入发生 badbit 或 eofbit 时,将引发异常 |
# 流状态影响
流状态用于表示流的情况,只有在全部 mask 位正常的情况下,返回值才为 true 。
如果希望程序在被设置流状态后继续工作(输入 or 输出),就必须保证流状态良好( mark 位全部正常)。
值得注意的是,如果是由于某个输入 or 输出导致状态异常。那么就算清理了 mark 状态,也没办法跳过这种「卡死状态」。
while( cin >> input){ | |
cout << input; | |
} | |
cin.clear(); // 如果不进行 clear 将无法进行后续的读取输入操作,因为 cin 的 mask 状态并不健康 | |
cin >> input; | |
cout << input; |
# 其他 istream 类方法
- 方法
get(char &)和get(void),提供不跳过空白的单字符输入功能。 - 函数
get(char*, int, char)和getline(char*, int, char)在默认情况下读取整行而非一个单词。
上述两种方法被称为非格式化输入函数,因为他们只读取字符输入,而不会跳过空白,也不进行数据转化。
# 单字符输入
get() 在没有参数或者参数为 char 类型时,都将读取下一个输入字符,即使该字符是空格、制表符或换行符。
get(char &)将输入值传递给 char 对象。get(void)将输入结果转为 int 类型返回。因此cin.get().get()将不能正常执行。

# 假设可以选择 >>,get(char &) 或 get(void) ,应该使用哪个更好呢?
如果想要跳过空白字符, >> 将会是个好选择,其他情况下更推荐使用 get(char &) 的版本。
# 字符串输入
get() 和 getline() 都需要传递一个用于放置字符串的内存地址和一个最大字符数。两者的区别在于:
get会把换行符留在输入流内,而getline会抽取并且丢弃输入流中的换行符。
此外还有第三个参数 —— 分界符,可以指定读取输入流中出现某个字符时,停止读取操作。
ignore() 函数和上述两个操作类似,但功能相反,其接受一个字符数和分界符作为参数:
- 字符数表示跳过输入流中的一定数量字符,分界符则表示遇到某个字符后该操作停止。
# 意外字符
- 当读取的文件达到文件尾时,将把
mark状态设置为eofbit - 当遇到流被破坏时(磁盘损坏等)将设置
badbit。 - 如果无输入(空行 or 直接达到文件尾)或者输入内容超过函数的指定字符数时,将设置
failbit。

# 其他 istream 方法
read():读取指定输入字符,读取结果不会在末尾加\0,因此不能之直接转换为字符串。常常配合write一起使用来操作文件读写。peek():返回下一个输入字符,但不从流中抽取该字符,因此可以反复读。gcount():返回最后一个非格式化抽取方法读到的字符数,一般用于获取读取的最大字符数,不过效率较低。putback():将一个字符插入到输入字符串中,被插入的字符将在下次读取时,第一个被读取到。
# 文件输入和输出
# 简单的文件 I/O
一个简单的写入程序可以分为以下三步:
- 创建一个 ofstream 对象来管理输入流
- 将该对象与特定的文件关联起来
- 以使用 cout 的方式来使用该对象,唯一的区别是输出将去到文件而非屏幕。
ofstream fout; | |
fout.open("text.txt"); | |
fout << "hello world"; |
同理,读取程序也是类似:
- 创建一个 ifstream 对象来管理输入流
- 将该对象与特定的文件关联起来
- 以使用 cin 的方式来使用该对象。
ifstream fin; | |
fin.open("text.txt"); | |
// ifstream fis("text.txt"); | |
string line; | |
getline(fin, line) |
# 文件模式
文件模式用于描述文件如何被使用:读、写、追加等。
之前介绍的关联文件操作中,都提供了第二个参数 —— 文件模式常量,用来描述文件如何被使用。
ifstream fin("text.txt", mode); //mode default = ios_base::in (打开文件以读取) | |
ofstream fout(); | |
fout.open("text.txt", mode); //mode default = ios_base::out | ios_base::trunc (打开文件以读取并截短文件) | |
// 截短文件表示将会把之前的内容删除,并重新写入。如果希望追加写入,则可以使用 ios_base::out | ios_base::app |
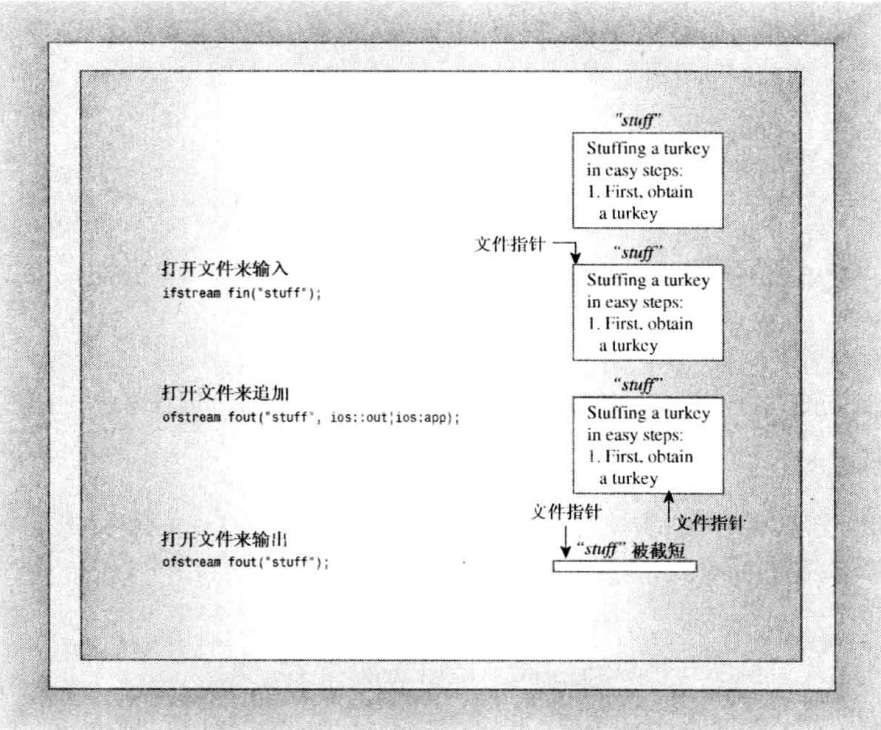

相比于 C++ 提供的 openmode 值,C 语言则使用字符来描述文件如何被使用,两者的对应关系如下:
- ate 和 app 都是将文件指针指向文件的尾部,不同之处在于 app 只允许将数据添加到文件尾部,而 ate 则单纯的把指针移到尾部,如何操作取决于程序。

# 二进制文件
数据在文件内的储存方式分为两种:文本 or 二进制。
文本格式和二进制格式对于字符的存储是一样的。但对于数字来说,两者的存储将会有很大的差别:

- 文本格式更易于阅读和修改,并且读取效率也较高。
- 二进制文件对于数据的存储更加精确,并且消耗的空间更小。
# 二进制文件和文本文件
二进制文件模式将程序数据从内存传输给文件,这个过程没有隐式转换。所以文件内得到的二进制数据将如你所预期的那样。
文本模式却并非如此:
- Window 文本文件使用「回车」和「换行」两个字符组合来表示「换行符」。
- Macintosh 文本文件使用「回车」来表示「换行符」。
- UNIX 和 Linux 文本文件则使用「换行」来表示「换行符」。
因此,C++ 程序在不同的平台上读写时,会对「换行符」的表述进行特定的转换以满足不同平台的规则。
二进制文件如果使用文本模式打开将会引发问题,由于 double 类型的值中间可能有和换行符的 ASCII 码相同的的位模式,从而导致解析有误,并且对于文件尾的检测方式也有区别,因此保存二进制数据时,最好使用二进制文本模式。
# 类对象的二进制存储
类对象如果要存储为二进制格式,其数据成员将被保留,而方法则不会,另外,如果有定义类的虚方法,则也将赋值隐藏指针(用于指向类的虚方法)。但由于下次读取类对象时,虚函数表的地址可能被修改,因此把虚函数指针存储在二进制文件内将可能会出现意料之外的问题。
# 流状态检查和 is_open ()
C++ 的文件流类从 ios_base 类那里继承了流状态成员,并且对其功能进行了以下扩展。
例如在打开一个不存在的文件进行输入时,将会设置 failbit 位。
由于 C++ 对于文件的操作引入了文件模式的概念,因此可能会出现由于文件模式不匹配导致的操作失败情况。
为此 C++ 提供了 is_open() 接口来判断文件是否正常被操作。
# 随机存取
随机存取是指不通过直接移动(依次移动)来访问文件的任意位置。对于有特定结构的数据来说,这样可以提供快速的访问途径,涉及接口:
seekp():将输入指针移动到指定位置。seekg():将输出指针移动到指定位置。
istream& seekg(streamoff, ios_base::seekdir); // 距离指定位置(seekdir)特定偏移(streamoff) | |
istream& seekg(streampos); // 距离文件起始位置(开头)特定距离(streampos) |
# 临时文件
C++ 库 cstdio 中提供了可以生成随机临时文件名的接口:
#include<cstdio> | |
char p[L_tmpnam] = { '\0' }; | |
for (int i = 0; i < 10; i++) { | |
tmpnam_s(p); | |
std::cout << p << std::endl; | |
} | |
// ---------- output ---------- | |
C:\Users\user\AppData\Local\Temp\ug2k.0 | |
C:\Users\user\AppData\Local\Temp\ug2k.1 | |
C:\Users\user\AppData\Local\Temp\ug2k.2 | |
C:\Users\user\AppData\Local\Temp\ug2k.3 | |
C:\Users\user\AppData\Local\Temp\ug2k.4 | |
C:\Users\user\AppData\Local\Temp\ug2k.5 | |
C:\Users\user\AppData\Local\Temp\ug2k.6 | |
C:\Users\user\AppData\Local\Temp\ug2k.7 | |
C:\Users\user\AppData\Local\Temp\ug2k.8 | |
C:\Users\user\AppData\Local\Temp\ug2k.9 |
# 内核格式化
iostream支持程序与终端之间的 I/O。fstream支持程序和文件之间的 I/O。sstream支持和 string 对象之间的 I/O。
读取 string 对象中的格式化信息或将格式化信息写入 string 对象中被称为内核格式化(incore formatting)。
头文件 sstream 定义了一个从 ostream 类派生而来的 ostringstream 类。
string my_name = "liming"; | |
ostringstream outstr; | |
outstr << "hello " << my_name; | |
string new_str = oustr.str(); // hello liming | |
outstr << " good job!" << endl; | |
string new_str_1 = oustr.str(); // hello liming good job! |