以下为个人学习笔记整理。参考书籍《C++ Primer Plus》
# 函数介绍
# C++ 内联函数
内联函数更像是把函数贴入到调用的位置,这样可以提高函数跳转所带来的开销。
声明内联函数:
- 在函数声明前加上关键字
inline; - 在函数定义前加上关键之
inline;
inline double square(double x){return x * x; } | |
int main(){ | |
double a = square(1.5); | |
return 0; | |
} |
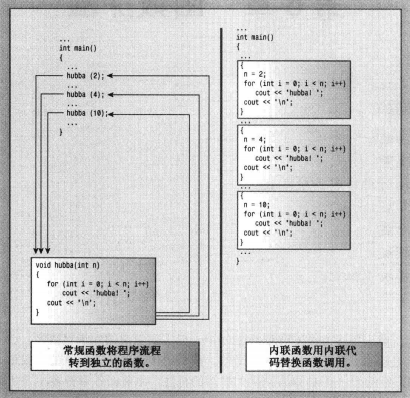
内联函数不支持递归调用。不要对复杂函数使用内联修饰。
# 内联与宏
- 宏并不是通过传递参数的方式来实现的,而是简单的文本替换。
# 引用变量
引用变量。相当于给变量构建一个新的别名,两个变量指代的是同一个内存地址。
值得注意的是,引用变量和指针并不一样。不能改变所指地址,
int & number_2 = number_1等效于int* const number_2 = &number_1。
# 引用变量的创建
int number_1 = 1; | |
int &number_2 = number1; // number_2 reference number_1 |
# 将引用作为函数参数
按引用传递和指针传递效果类似,可以在函数内部修改传入的对象。
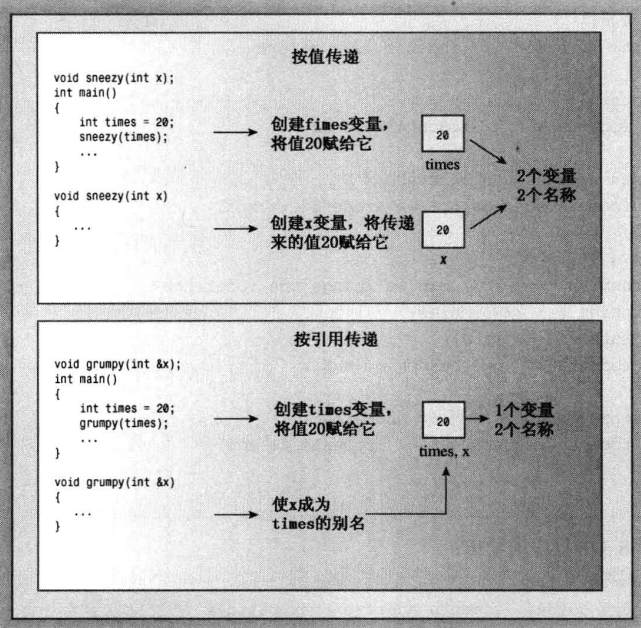
# 尽可能的使用 const
const可以避免无意中对引用内容的修改。const可以兼容const参数和非const参数。- 使用
const引用,可以让函数正确生成临时变量。
# 左值和右值
- 左值存放在对象中,有持久的状态。(变量名)
- 右值要么是字面常量,要么是在表达式求值过程中创建的临时对象,没有持久的状态。
# 右值引用
一种指向右值的引用。左值引用是将一个左值传递给另一个。右值引用是将一个右值传递给一个左值。
int left_ref = 100; | |
int& left_ref_1 = left_ref; // 左值引用 | |
int&& left_ref_2 = 100; // 右值引用 |
# 参考链接:
- 谈谈 C++ 中的右值引用。
# 将引用用于结构
避免返回结果里的结构是函数内生成的临时变量。(离开函数后就销毁了)
- 使用 new 来初始化对象并分配内存。
- 使用 「引用参数」 作为返回值。
用 const 修饰需要返回的引用,可以避免出现如下的代码:
func(number_1, number_2) = number_3;:这样的写法会导致最终的返回值被number_3覆盖。
# 何时使用引用参数
- 程序能够修改参数内容。
- 复杂的参数,往往传递引用。这样可以提高效率。
- 对于数组和指针,传递引用是唯一的选择。最好能够设置为 const 类型。
- 如果数据对象是类或者结构,只能使用指针。
# 函数模板
通过使用「泛型」来定义一套通用的参数类型。
template <typename T> | |
void add(T any_a, T any_b) { | |
cout << any_a + any_b << endl; | |
} |
c++98 支持用 class 代替 typename,但推荐还是用 typename。
# 显式具体化
# 定义标准(ISO/ANSI C++ 标准):
- 对于给定的函数名,可也有非模板函数,模板函数和显式具体化模板函数以及它们的重载版本。
- 显式具体化的原型和定义应该以
template <>作为开头,并指出typename的类型。 - 调用优先级:非模板函数 > 显式具体化模板函数 > 模板函数。
// 非模板函数 | |
void tp_func(int& a, int& b) { | |
cout << "tp_func 非模板函数" << a << b << endl; | |
} | |
// 模板函数 | |
template <typename T> | |
void tp_func(T& a, T& b) { | |
cout << "tp_func 模板函数" << a << b << endl; | |
} | |
// 显式具体化模板函数 | |
template <> void tp_func<double>(double& a, double& b) { | |
cout << "tp_func 显式具体化模板函数" << a << b << endl; | |
} | |
int main(){ | |
double&& mm = 1; | |
double&& nn = 2; | |
tp_func(mm, nn); // 显式具体化模板函数 | |
int&& mkkm = 1; | |
int&& nkkn = 2; | |
tp_func(mkkm, nkkn); // 非模板函数 | |
float&& mffm = 1; | |
float&& nffn = 2; | |
tp_func(mffm, nffn); // 模板函数 | |
return 0; | |
} |
# 实例化和具体化
函数模板的并不会生成函数的定义,只是一个生成方案。只有在编译的时候,才会为特定的函数调用生成相应的函数定义 —— 模板实例(instantiation)
编译时才确定函数定义的实例化,被称为隐式实例化(implicit instantiation)。
通过
template来进行实例化的操作。被称为显式实例化(explicit instantiation)。
# 显式实例化和显示具体化意义不同!!!
- 显式实例化:
template void tp_func<int>(int, int)。通过模板函数生成一个模板实例。 - 显式具体化:
template<> void tp_func<int>(int, int)。不通过模板函数生成一个模板实例。
如果同时出现定义相同的「显式实例化」和「显式具体化」函数,将会出错。
# 编译器选择哪个版本的函数??
假设有下面几个函数定义:
void f(int); //# 1 | |
float f(float, float=3); //# 2 | |
void f(char); //# 3 | |
char* f(const char*); //# 4 | |
char f(const char&); //# 5 | |
template<typename T> void f(const T&); //# 6 | |
template<typename T> void f(T*); //# 7 |
调用函数:
f('A'); // arg type is char -> implicit conversion int |
只考虑参数不考虑返回值的情况:首先排除 #4 和 #7 ,由于它们都需要「指针类型」参数,而 C++ 会把 char 隐式转化为 int ,但无法转化为「指针类型」。
对于函数重载,函数模板和函数模板重载,C++ 定义了一套调用顺序:
- step1:创建「候选函数列表」,其中包含与被调用函数名称相同的函数和函数模板。
- step2:使用「候选函数列表」生成「可行函数列表」。这些都是参数数目正确的函数。这里会存在隐式转化的匹配。例如参数是
float类型,隐式类型转化会把类型转为double,从而匹配上double类型的函数。 - step3:确定最佳的可行函数。选取规则:
- 选取之前,需要对函数参数进行转换,转换优先级如下:
- 完全匹配,但 常规函数 > 模板。
- 提升转换 (例如:
char和shorts自动转为int,float自动转为double)。 - 标准转换(例如:
int转为char,long转为double)。 - 用户定义转换。
- 选取之前,需要对函数参数进行转换,转换优先级如下:
考虑选取顺序:
函数 #1 会优于 #2,因为
char到int的转化是「提升转换」,而char到float的转化是「标准转换」函数 #3 #5 #6 会优于 #1 #2,因为它们都是完全匹配
函数 #3 和 #5 又会优于 #6,因为 #6 是模板函数
# 思考:什么是「完全匹配」?
C++ 在进行匹配的过程中,允许一些「无关要紧的转换」。如下这些类型都算作是「完全匹配」:
| 从实参 | 到形参 |
|---|---|
| Type | Type & |
| Type & | Type |
| Type [ ] | * Type |
| Type(arguement-list) | Type(*)(arguement-list) |
| Type | const Type |
| Type | volatile Type |
| Type * | const Type |
| Type * | volatile Type * |
假设函数调用代码如下:
struct blot {int a;}; | |
blot ink = {25}; | |
recycle(ink); |
能够和它「完全匹配」的函数定义:
void recycle(blot); //#1 | |
void recycle(const blot); //#2 | |
void recycle(blot &); //#3 | |
void recycle(const blot &); //#4 |
- 函数 #3 优先于 #4,由于非 const 数据的指针和引用要优先于 const 数据的指针和引用。
- 函数 #1 和 #2,由于是非指针或者引用参数,所以无法区分优先级,会导致「二义性」(ambiguous)错误。
- 「非模板函数」 > 「显式具体化模板函数」 > 「隐式模板函数」。
- 两个「完全匹配」的模板函数,更具体的模板函数优先。
# 更具体(most specialized)
「更具体」并不意味着显式具体化,而是指编译器再推断类型的过程中,尽可能少的进行类型转换。
template <typename T> void ff(T t); //#1 | |
template <typename T> void ff(T* t);//#2 | |
struct blot{int a;}; | |
blot ink = {2}; | |
ff(&ink); // #2 更具体 |
由于实参是 blot 的地址(指针)。所以 #2 的 typename T 被解释为 blot 。而 #1 的 typename T 被解释为 blot* 。
# 函数优先级汇总:
「完全匹配」>「提升转换」>「标准转换」>「用户定义转换」。
完全匹配情况下:
- 「非模板函数」 > 「显式具体化模板函数」 > 「隐式模板函数」。
- 都是模板函数的情况下,「更具体」的优先。
- 非 const 数据的指针和引用要优先于 const 数据的指针和引用。
在函数调用过程中,可以指定函数优先选择模板定义:
再调用函数的名称后面加上 <> 可以优先匹配模板函数。
template<typename T> | |
T lesser(T a, T b); //#1 | |
int lesser(int a, int b); //#2 | |
int x = 1; | |
int y = 2; | |
double m = 1.1; | |
double n = 2.2; | |
lesser(x,y) // call #2 | |
lesser(m,n) // call #1 with double | |
lesser<>(x,y) // call #1 with int | |
lesser<int>(m,n) // call #1 with int |
# 模板函数的发展
# 关键字 decltype(C++11)
C++11 新增的关键字 decltype 提供了一种解决推断类型的问题。例如:
如下情况下在 C++98 中, xpy 的类型将无法确定,他可能是 T1 ,也可能是 T2 ,也可能是其他类型。
// C++ 98 问题 | |
template<typename T1, typename T2> | |
void tf(T1 x, T2 y){ | |
?type? xpy = x + y; | |
} | |
// C++ 11 处理办法 | |
void tf(T1 x, T2 y){ | |
decltype(x + y) xpy = x + y; | |
} |
假如有如下声明:
decltype(expression) var; |
- 如果
expression没有被括号括起来,则var的类型和expression相同。decltype(x) var; - 如果
expression是一个函数调用,则var的类型是函数的返回值。decltype(f()) var; - 如果
expression是一个左值(变量),则var的类型是左值的引用。decltype((左值)) var; - 如果
expression不满足以上三种情况,则var的类型和expression相同。decltype(x+1) var;decltype(100) var;
# 新的问题
如果函数的返回值类型是如下的情况,将没有办法通过 decltype 来定义返回值类型,因为在函数声明之前变量 x 和 y 还没有被定义。
template<typename T1, typename T2> | |
?type? tf(T1 x, T2 y){ | |
return x + y; | |
} |
auto 可以帮助我们解决这个问题:
template<typename T1, typename T2> | |
auto tf(T1 x, T2 y) -> decltype(x + y){ | |
return x + y; | |
} |