以下为个人学习笔记整理。参考 PhysX SDK 3.4.0 文档,部分代码可能来源于更高版本。
# PhysX——Serialization 篇
本文基于实现的角度,对 PhysX 中序列化和反序列化相关内容做了比较详细的梳理。对于想要了解其中原理或者希望动手修改序列化内容的开发者应该有所裨益。
# 概述
和其他的序列化程序不同,PhysX 中的对象由于存在着些许依赖关系。因此需要花费较大的精力在关系图的建立上,这也是整个序列化流程中较为重要的一环。
# 常用容器介绍
让我们先来看看序列化中常见的几个容器,这有助于我们理解序列化中对于关系的处理:
# Collection
Collection 是用来存放序列化对象的容器,PhysX 提供了从 Scene -> Collection -> Binary -> Collection -> Scene。Collection 可以理解为内存对象到二进制文件转换过程的临时容器。开发者只需把应该序列化的对象装入 Collection,剩下的工作都可以交给 PhysX 内部进行处理:
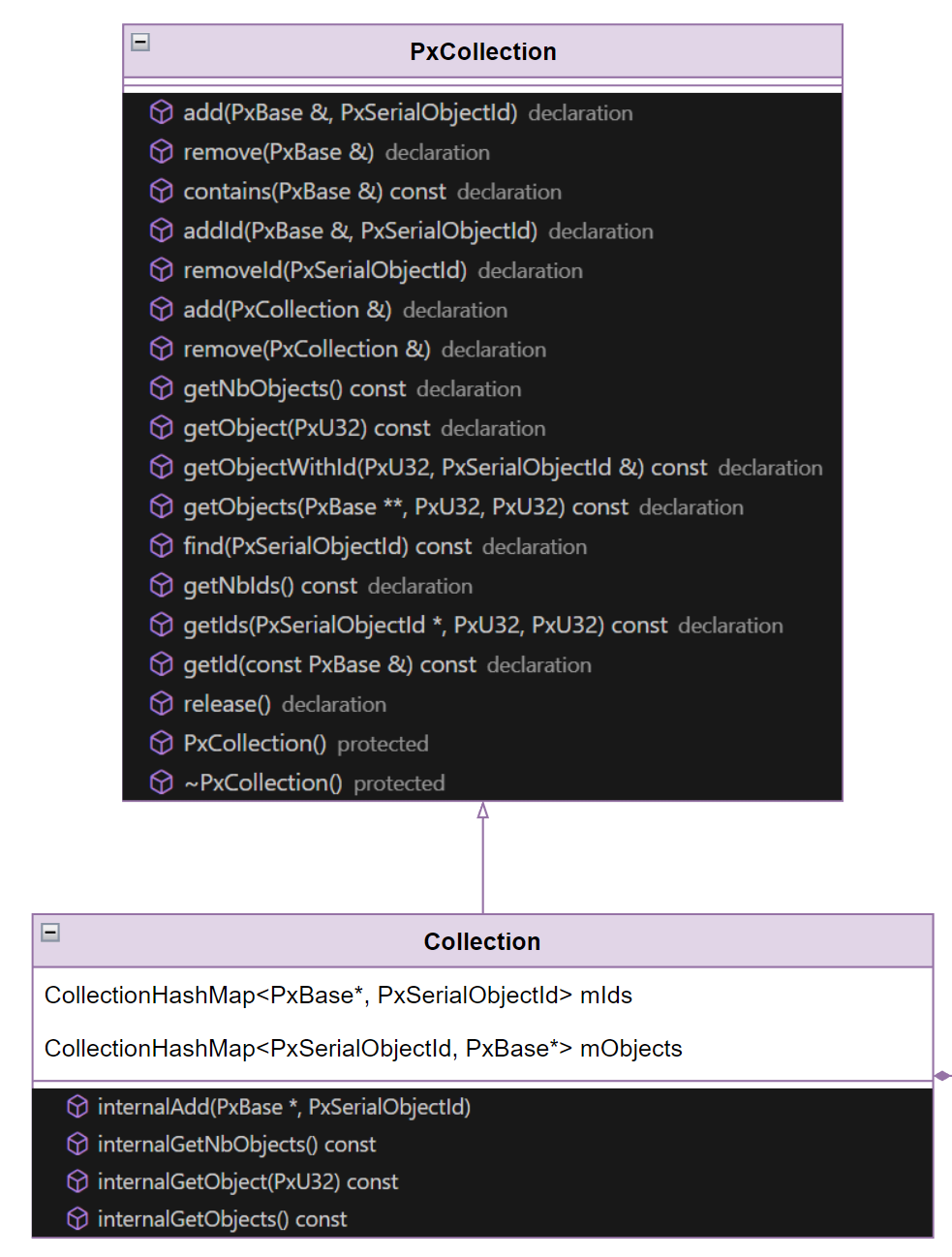
整个结构并不复杂,只有两个容器对象:
- mIds:对象指针和序列化编号的 HashMap。
- mObjects:序列化编号和对象指针的 HashMap。
# HashMapBase
HashMapBase 是整个序列化过程中最常用到的数据结构,提供高效的插入删除查询功能,并支持动态扩容。此外其派生类 CoalescedHashMap 还支持高效的随机访问功能:
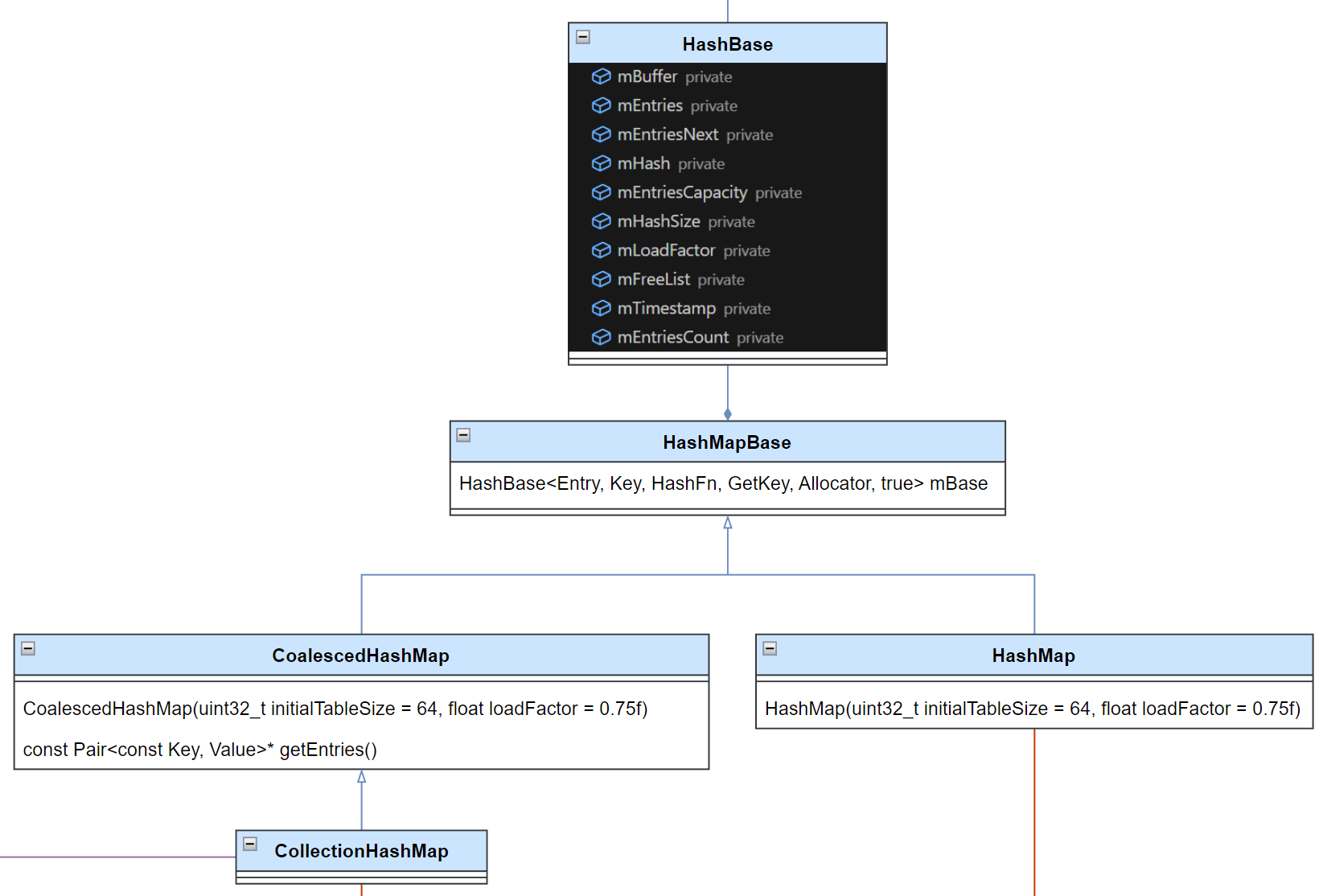
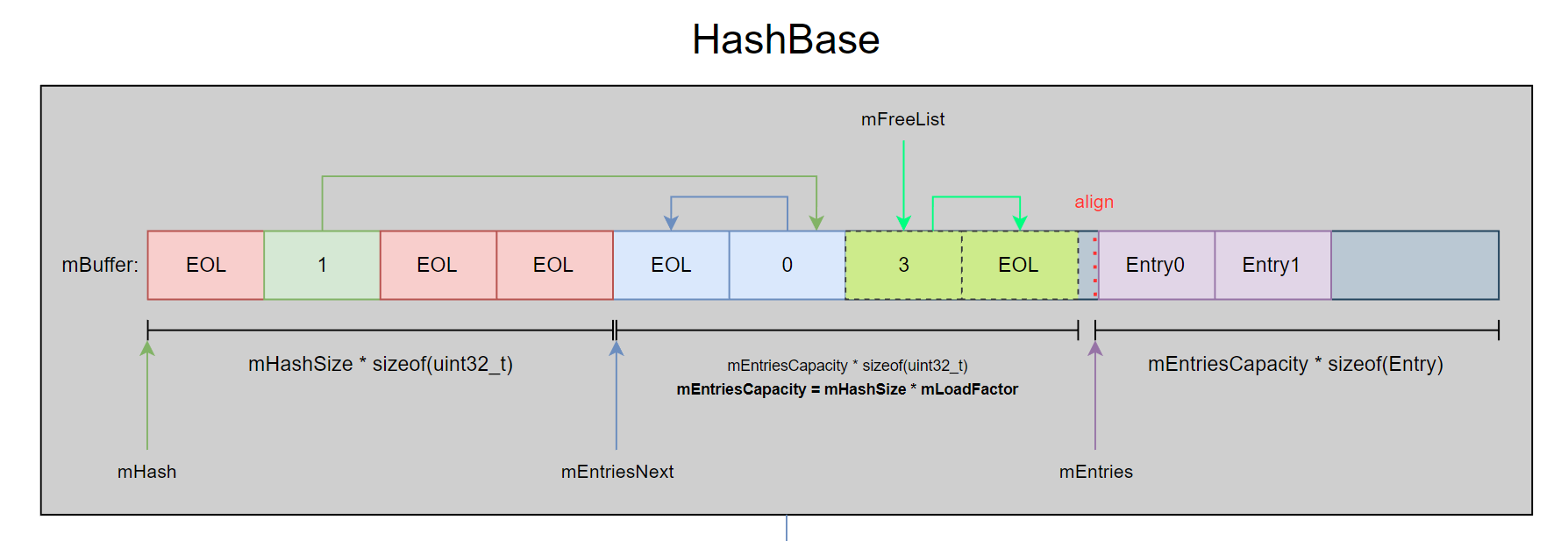
HashMapBase 的核心是 HashBase,整个 HashBase 是一块完整、连续且紧凑的内存空间。主要分为三部分内容:
- 哈希桶(mHash)。
- Next 对象指针(mEntriesNext):当出现 Hash 冲突的时候,根据对象 Next 指针关联下一个元素索引,哈希桶本质上是个头指针。
- 对象列表(mEntries)。
# CollectionSorter
CollectionSorter 继承自 PxProcessPxBaseCallback,该基类定义了一个填充接口用于子类实现。
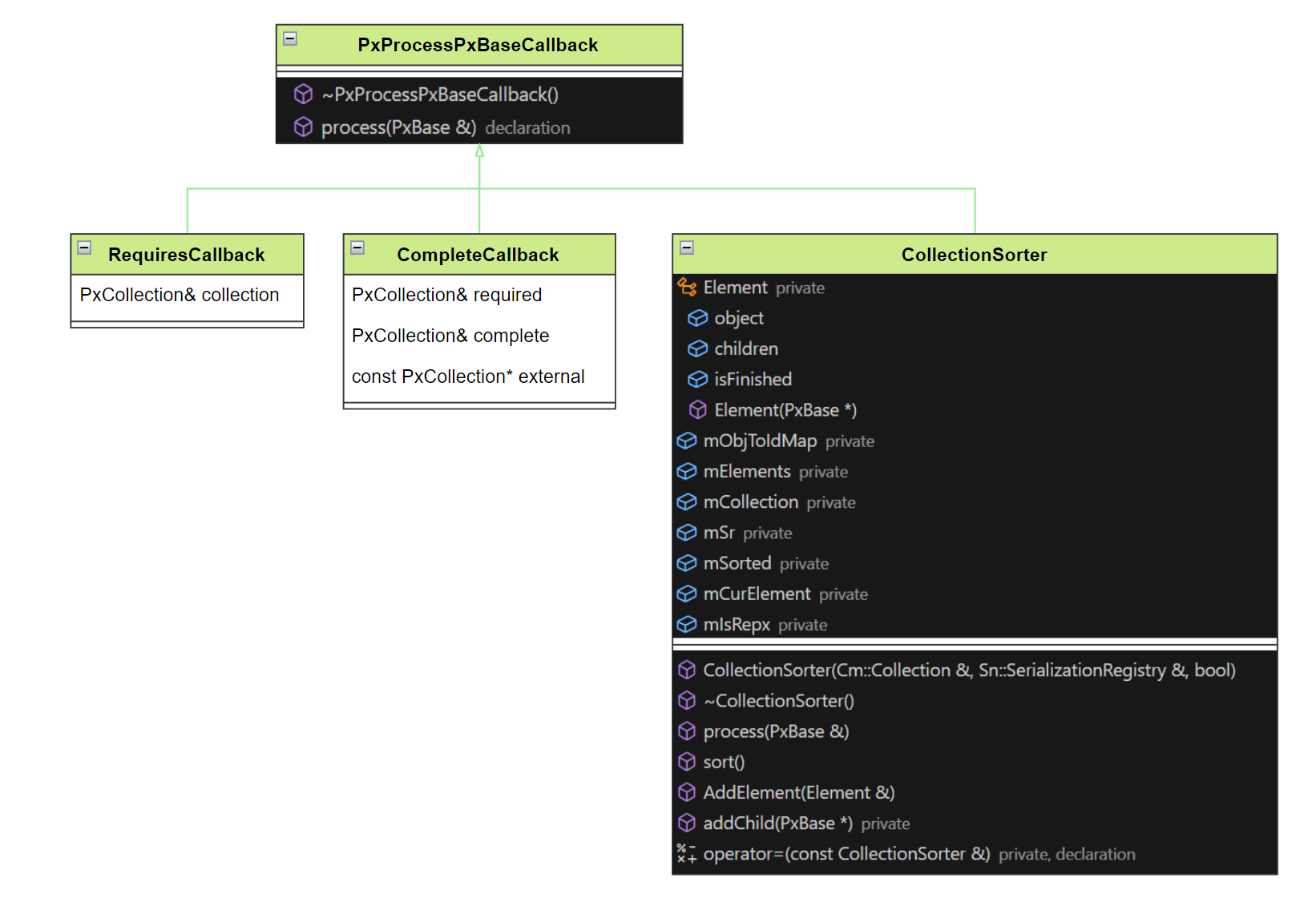
CollectionSorter 通过该接口实现了依赖关系的补全,通过 Element 记录每个对象和其关联对象 children。然后根据 sort 函数对结果进行排序,把 children 放在 father 前面,这样导出和导入的时候就可以根据依赖按序补全关系结构图。
# SerializationContext
SerializationContext 是整个序列化反序列化中比较关键的一环。前面提到了 PhysX 不仅仅要处理对象的储存,还需要记录各个对象间的关联关系。
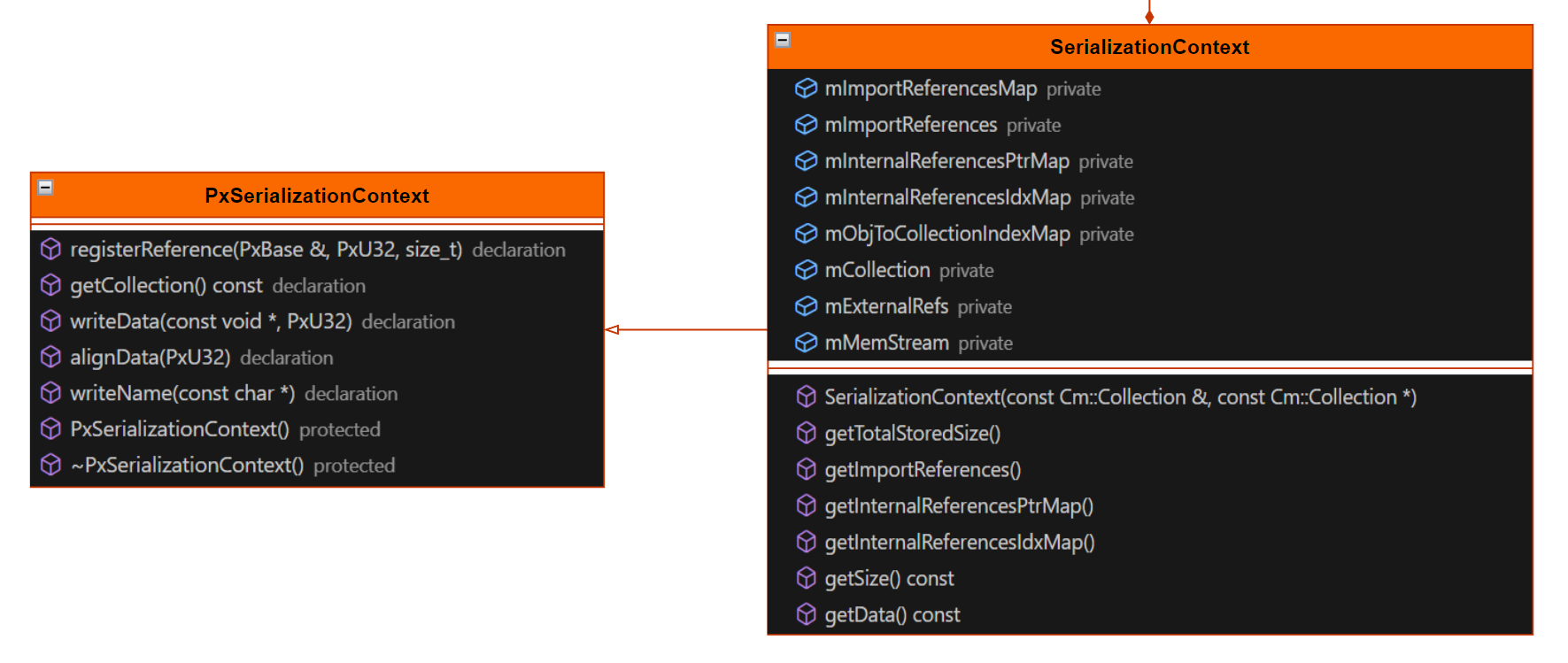
目前的关联关系主要有三种:
- import reference:外部引用。表示部分引用内容在其他 Collection 内,对于分类型导出的时候比较有效。
- internal ptr reference:内部地址引用。用地址编号作为引用 ID。
- internal idx reference:内部编号引用。用某些对象特有的标识 ID 作为引用 ID。
# 序列化流程
- 【step.1】对象收集:顾名思义,就是将需要序列化的对象统统收纳进 Collection 容器内。
- 【step.2】对象补全:由于添加序列化对象是一项人为操作,一些依赖的对象很可能会漏掉,因此 PhysX 提供了一件补全的功能,尽可能保证依赖的完整性。这一步实际上是利用各类对象自身的
PxSerializer::requiresObjects函数完成依赖的收集:
void PxSerialization::complete(PxCollection& collection, PxSerializationRegistry& sr, const PxCollection* exceptFor, bool followJoints) | |
{ | |
PxCollection* curCollection = PxCreateCollection(); | |
PX_ASSERT(curCollection); | |
curCollection->add(collection); | |
PxCollection* requiresCollection = PxCreateCollection(); | |
PX_ASSERT(requiresCollection); | |
do | |
{ | |
getRequiresCollection(*requiresCollection, *curCollection, collection, exceptFor, sr, followJoints); | |
collection.add(*requiresCollection); | |
PxCollection* swap = curCollection; | |
curCollection = requiresCollection; | |
requiresCollection = swap; | |
(static_cast<Cm::Collection*>(requiresCollection))->mObjects.clear(); | |
}while(curCollection->getNbObjects() > 0); | |
requiresCollection->release(); | |
curCollection->release(); | |
} |
- 【step.3】序列化过程 ——PxSerialization::serializeCollectionToBinary。
- 【step.3.1】对象基于依赖关系排序:
PxSerialization::complete只能保证导出内容基本的完整性,各对象之间的引用关系是没有进行梳理的,因此需要在导出之前进行系统性的梳理,并且需要依照依赖关系,把依赖者放在被依赖者的后面,这里就是通过 CollectionSorter 实现的。 - 【step.3.2】引用关系分类:由于 PhysX 内定义了很多的引用方式,例如通过 ID 的引用,亦或是通过对象指针的引用。在导出时肯定各不相同,因此需要再归个类,方便分类型把关系进行导出。这里通过 SerializationContext 记录不同种类的导出关系。
- 【step.3.3】具体的导出步骤:
- 头文件导出:版本号,平台之类的基本信息,用于校验。
- manifest 信息导出:记录各个对象的起始地址和对象类型。
- import reference 外部引用类型导出:记录着引用了外部其他容器内的对象的相关信息。
- export reference map 内部基于 ID 引用的映射表:用于恢复的时候快速通过 ID 查询下标定位对象。
- internal ptr reference 内部指针类型引用导出:基于对象指针所指地址编号作为对象的唯一标识所记录的引用信息。
- internal idx reference 内部 ID 类型引用导出:基于对象 ID 作为唯一标识所记录的引用信息。
- export data 对象本身的导出内容:sizeof (class type)。
- export extra data 对象的额外导出内容:用户自定义。
- 【step.3.1】对象基于依赖关系排序:
# Binary 格式图
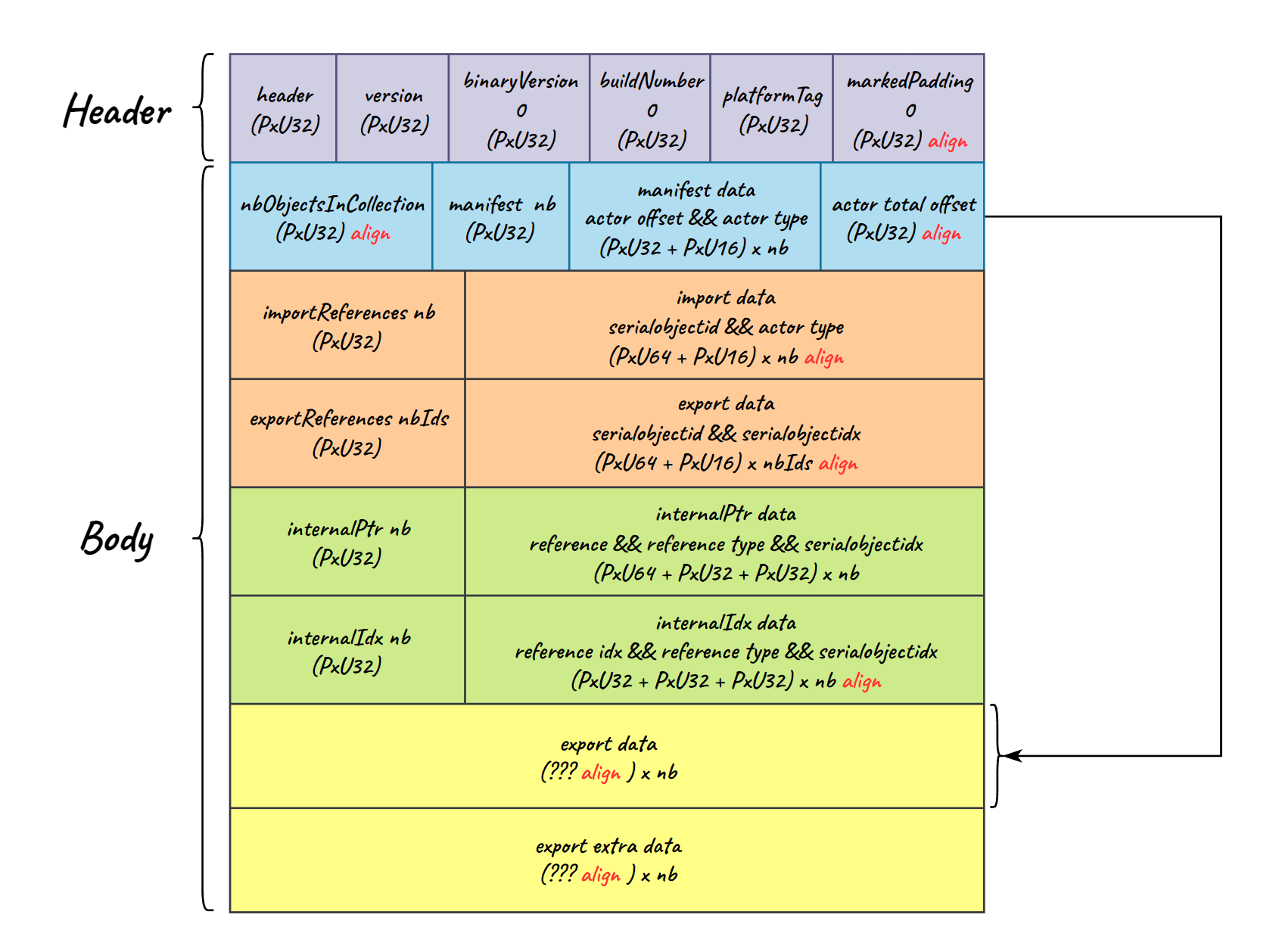
- Header 部分不做过多解释。
- nbObjectsInCollection:Collection 内的对象数量。
- manifest nb:实现了 Serialization 具备可序列化性质的对象数量。
- manifest data:依据顺序记录各个对象的导出类型。
- actor total offset:对象导出后占用的总空间大小,用于最后续反序列化对象后的偏移,对应于 export data size。
- importReferences nb && data:外部引用,表示该 Collection 引用了外部对象,有点类似外链接的感觉。由于现在导出都是全依赖导出形式,因此基本上不存在外部依赖的情况,可以不用过多关注。
- **exportReferences nb && data:** 内部引用,导出内部对象的 ID 和对应的下标。可以在做依赖恢复的时候提高效率。
- **internalPtr nb && data:** 内部引用关系,通过对象在序列化数据内的偏移地址作为索引。
- **internalIdx nb && data:** 内部引用关系,通过对象在序列化数据内的 id 作为索引。
- export data && export extra data:对象的实际数据,包含两个部分。export data 表示对象的基本信息。extra data 则更偏向于用户自定义数据。
# 反序列化流程
todo...