以下为个人学习笔记整理。参考 PhysX SDK 3.4.0 文档,部分代码可能来源于更高版本。
# 「Scene Queries」AABBPruner
本篇基于 「Scene Queries」AABBTree 的扩展,阅读之前建议先了解 AABBTree。( ̄︶ ̄)↗
如果说 AABBTree 是场景查询中最基础的数据结构,那么 AABBPruner 则是再此基础上进行了全方位的优化 —— 交替帧渲染。该理论的核心是同时存储画面 A 和画面 B,其中一个展示给用户,另一个则在后台渲染,等到渲染完成后,对两者进行替换,从而实现流畅的观看体验。同理,为了保证 AABBTree 能够时刻提供场景查询功能、保证增删改的实时性,同时还可以兼顾执行效率和空间利用率,这种交替帧渲染无疑是一个比较好的方案。
首先要明确的一点是,这种方案并不是必须的,即使不使用交替帧渲染,依旧可以实现场景查询以及实时增删改,只不过执行效率和空间利用率会比较低。
接下来就从 AABBPruner 基础结构开始一点点介绍其中的实现细节:
# AABBPruner 中的数据组成
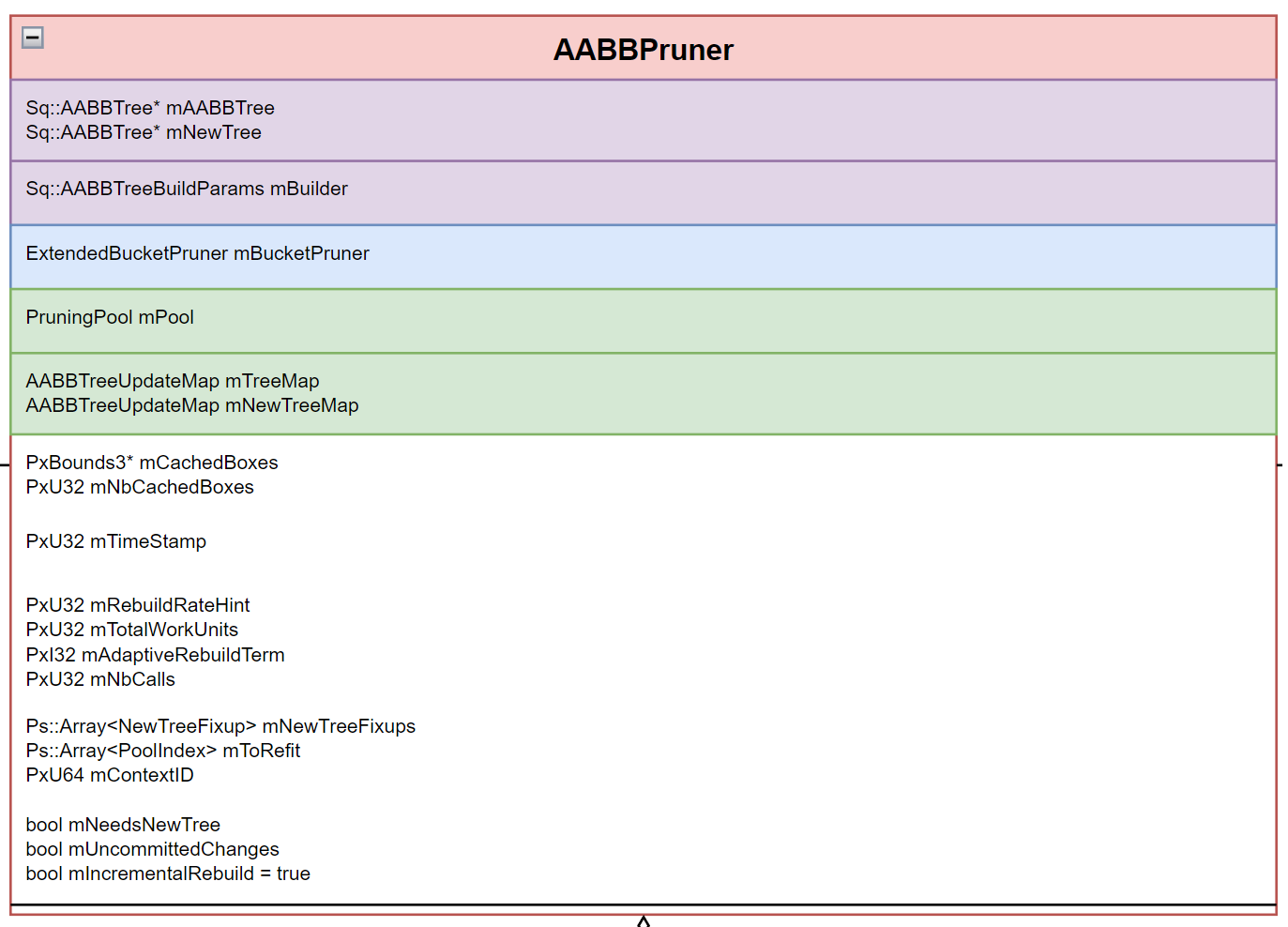
- mAABBTree && mNewTree:两棵 AABBTree。一棵是当前正在使用的 AABBTree,另一棵是正在后台构建中的 AABBTree。
- mBuilder:构建 mNewTree 时临时存储的构建配置信息。
- mBucketPruner:ExtendedBucketPruner 结构,负责对新增节点做增量构建的 IncrementAABBTree 管理结构。
- mPool:维护所有对象的 bound、shape、actor 关系,同时也是构建 AABBTree 和 IncrementAABBTree 的数据来源。
- mTreeMap && mNewTreeMap:分别记录了 mAABBTree 和 mNewTree 中 bounds 和 AABBRuntimeNode 的映射关系。
- mCachedBoxes && mNbCachedBoxes:临时缓存某个时刻 mPool 中的 bounds 数据,用来作为构建 mNewTree 的源数据。
- mTimeStamp:时间戳,每次构建新的 mNewTree 都会 + 1,也可以理解为帧号,区分不同时刻的修改。
- mNbCalls && mRebuildRateHint && mTotalWorkUnits && mAdaptiveRebuildTerm:四个变量实现构建工作的预估
- mNbCalls:表示当前构建耗费了多少 frame。
- mRebuildRateHint:表示预计需要多少 frame。
- mTotalWorkUnits:表示本次构建预计需要多少的工作量。
- mAdaptiveRebuildTerm:表示之前工作预估的准确性,该值会受到 mNbCalls && mRebuildRateHint 影响,并影响 mTotalWorkUnits 计算。
- mNewTreeFixups:记录 mNewTree 构建过程中被移除的包围盒和会被顶替到移除位置的包围盒下标。
- mToRefit:记录 mNewTree 构建过程中发生变化的包围盒下标。
- mContextID:上下文 ID,一个 AABBPruner 持有一个,用来唯一标识。
- mNeedsNewTree:标识是否需要构建 mNewTree,在包围盒发生变化且支持增量构建(mIncrementalRebuild = true)的情况下,该标志为 true。
- mUncommittedChanges:标识有修改需要被 commit。commit 会让修改生效在 mAABBTree 上,如果 mNewTree 构建完成情况下还会进行树替换。并且在 commit 没有执行完毕的情况下,不允许执行查询操作。
- mIncrementalRebuild:是否支持增量构建的标记。不支持的情况下每次 commit 都会在当前帧内重新构建一棵新的 mAABBTree,否则会分布构建 mNewTree 并在构建完成后通过 commit 对 mAABBTree 进行替换。
其中有几个陌生的结构之前没有提及,这里先简单的介绍一下:
# PruningPool
PruningPool 有如下四个主要的存储结构:
PxBounds3* mWorldBoxes:所有对象的 Bound 数据PrunerPayload* mObjects:所有对象的 Shape 及 Actor 对象地址PrunerHandle* mIndexToHandle:index 和 handle 的映射列表PoolIndex* mHandleToIndex:handle 和 index 的映射列表
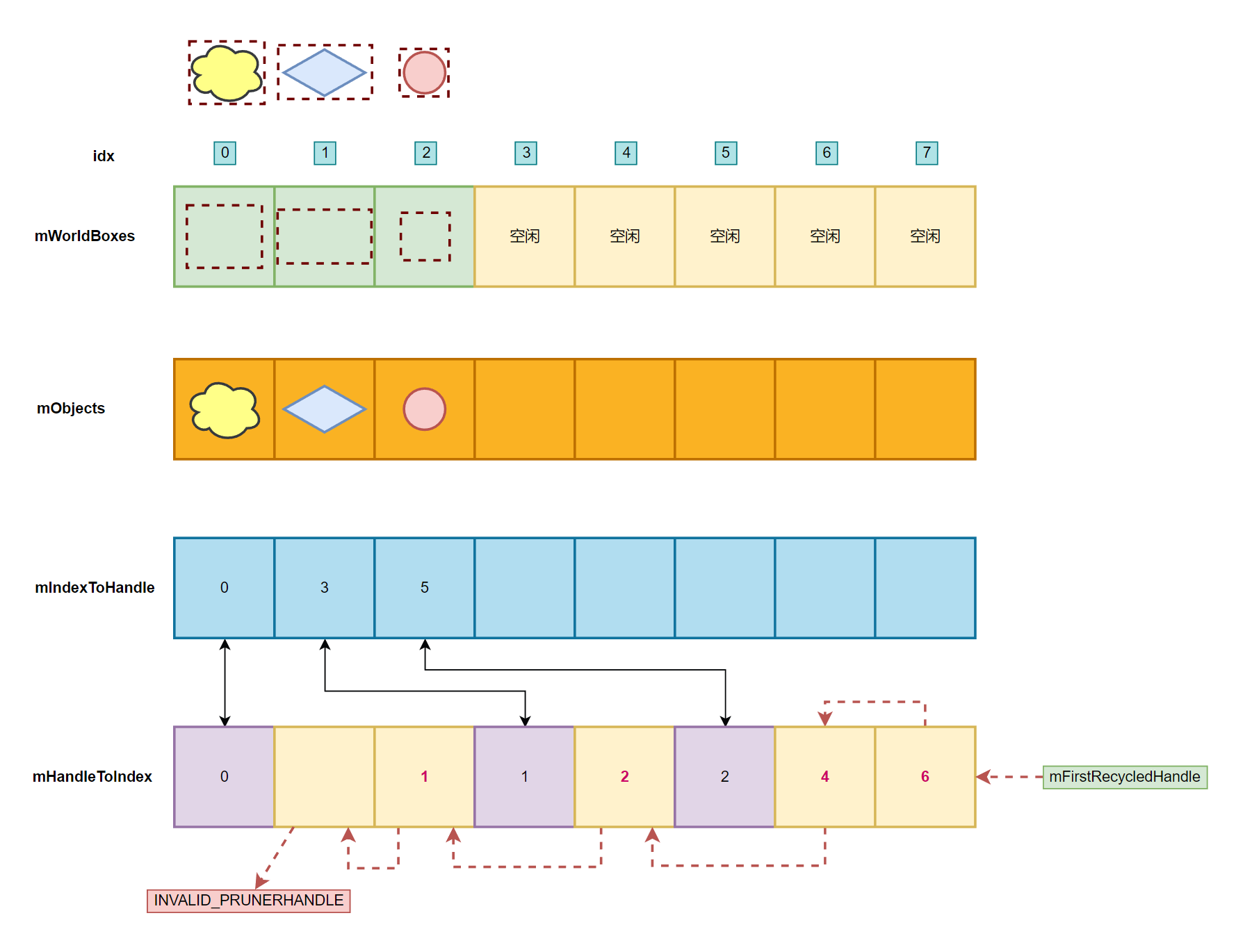
PruningPool 用来存储 PrunerPayload 和 AABBBound 关联的对象列表,PrunerPayload 中存储了两个指针,分别指向 Bound 所属的 Shape 和 Actor。之前介绍 AABBTree 构建中 AABBTreeBuildParams.mAABBArray 的数据也来源于这里的 mWorldBoxes。
前三个数组是对齐的,同一下标获取到的信息同属于一个对象。而 mHandleToIndex 和 mIndexToHandle 形成了一组映射结构。外部通过 mHandleToIndex 访问内部数据,内部数据调整也需要同步修改 mIndexToHandle 映射关系,另外还有个 mFirstRecycledHandle 用于指向第一块空闲的 mHandleToIndex。
# removeObject
PruningPool 移除对象有着一些特殊规则,很大程度也影响了整个 AABBPruner、AABBTree、IncrementAABBTree 的实现。
移除对象的时候被删除节点对应的 mHandleToIndex 会头插到 mFirstRecycledHandle 指向的单链表。这时候 mObjects 、mWorldBoxes、mIndexToHandle 可能会因为删除操作而导致内存不连续。为了保证连续(连续性会影响拷贝和遍历)会把最后一个元素用于填补空缺,因此还有一个替换操作。
例如这里删除掉第 1 个包围盒,然后用第 3 个进行替换:
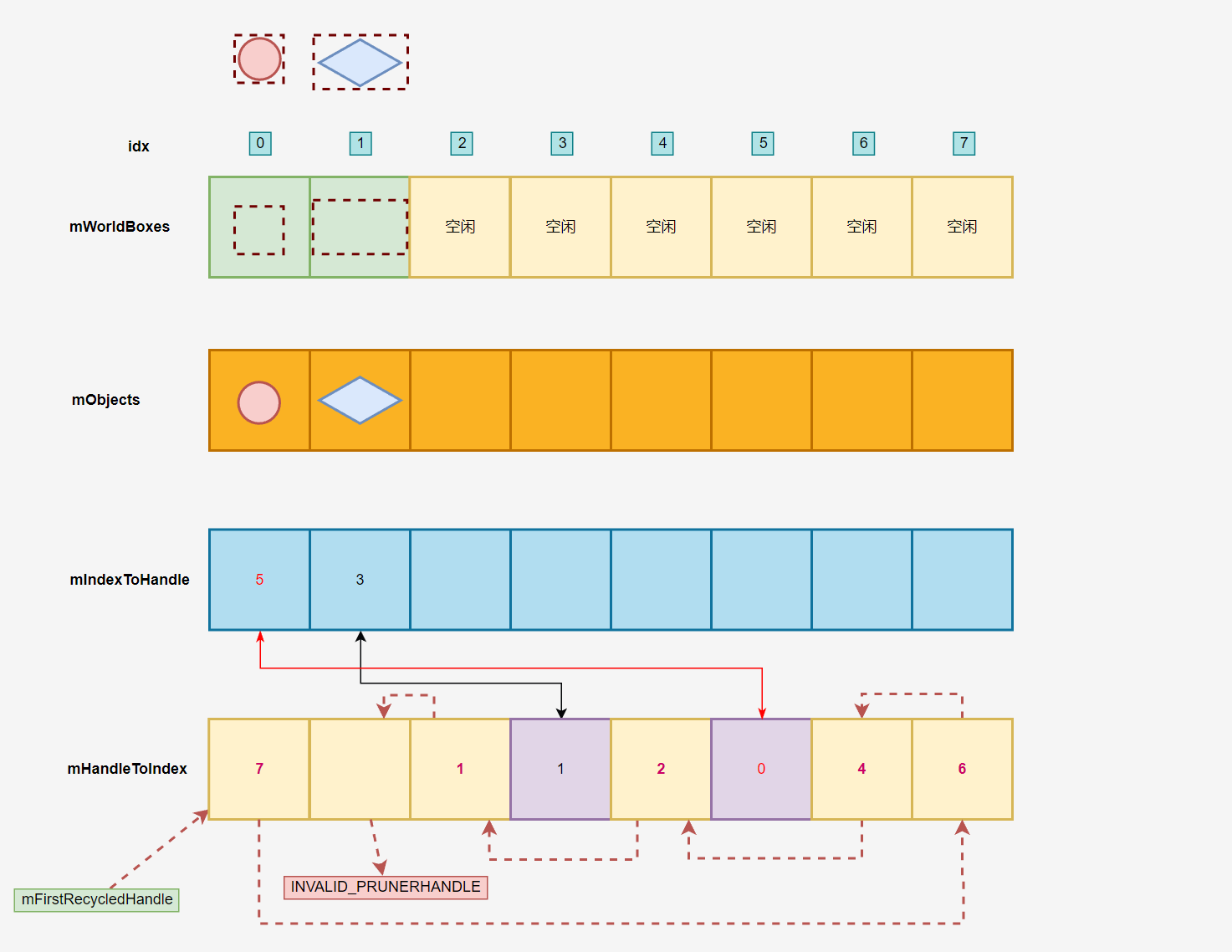
这种替换操作可以使得「空间分布比较紧凑」、「移除节点的复杂度 O (1),不需要对所有后置数据做平移」,代价是打乱了 mWorldBoxes 内两个包围盒的位置,而 AABBTree 和 IncrementAABBTree 的构建都会记录 Box 的位置用于访问,位置变更了需要批量修改非常麻烦,因此还单独维护了一个 mHandleToIndex,这样外部只需要记录 mHandleToIndex 下标即可,无需担心内部的位置发生变化。
风险点:可以看到 mHandleToIndex 存储的内容可能是自己的下一个空闲节点也可能是 mIndexToHandle 下标,两者的数值可能相同,然而访问 Pool 的时候是通过 Handle 下标来的,因此很可能明明是个空闲节点,但依旧可能访问到数据。例如 mHandleToIndex[2] 和 mHandleToIndex[3] 最终都会指向 mIndexToHandle[1],这点上 PhysX 并没有增加严格的保护手段。
# ExtendedBucketPruner
ExtendedBucketPruner 中比较关键的结构是 MainTree 、MergedTree,以及 PrunerCore。
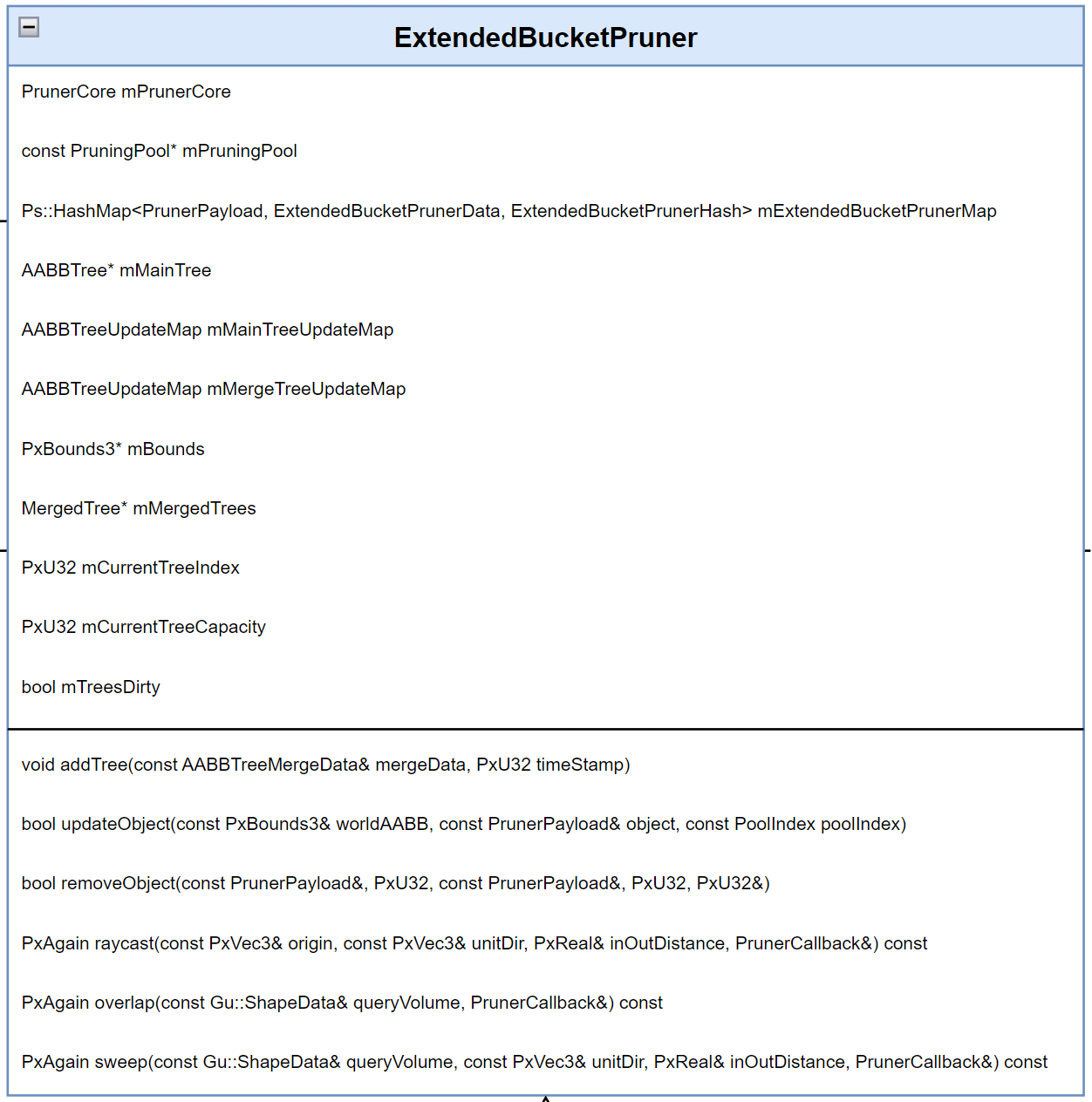
mMergedTrees:其中 mMergedTrees 是一棵棵的 AABBTree。因为 PhysX 不仅支持向场景内添加单个 Actor,还支持多个 Actor 打包成 PruningStructure 添加到场景,这里就不做过多展开,简单理解就是除了支持添加一个树节点以外,还支持添加整棵树,mMergedTrees 就是那个存储树的结构。
mMainTree:mMainTree 也是一棵 AABBTree,构建的数据是基于所有 MergedTree 的根节点包围盒。由于数据量不大,因此每次新增或者删除 MergedTree 的时候都会进行全量重建。
# IncrementalAABBPrunerCore(PrunerCore)

简单来说 IncrementalAABBPrunerCore 存储了两棵 CoreTree,每个 CoreTree 内维护了一棵 IncrementalAABBTree 所需的全部数据,至于为什么是两棵,我们后面再说。
- mChangedLeaves:用来记录每次变更操作导致映射关系发生改变的节点。并在变更操作执行完毕后更新 CoreTree 的 mapping 映射。
- mPool:指向的是 AABBPruner.mPool。
- mCurrentTree && mLastTree:标识当前使用的树和上次用过的树下标。因为只有两棵树,其实理论上记录一个就可以了。
# CoreTree
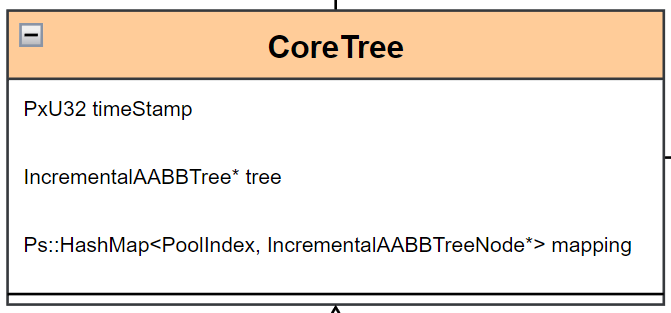
CoreTree 比较简单,存储了一个 IncrementAABBTree、一个 bound 到 TreeNode 的映射,以及这棵树最后一次修改的时间戳。时间戳是用来评估这棵树的有效性的,这个后面交替渲染部分再做介绍。
# ExtendedBucketPruner 结构图
下图是一张简单版的 ExtendedBucketPruner 结构图,为方便更好的理解省去了很多细节:
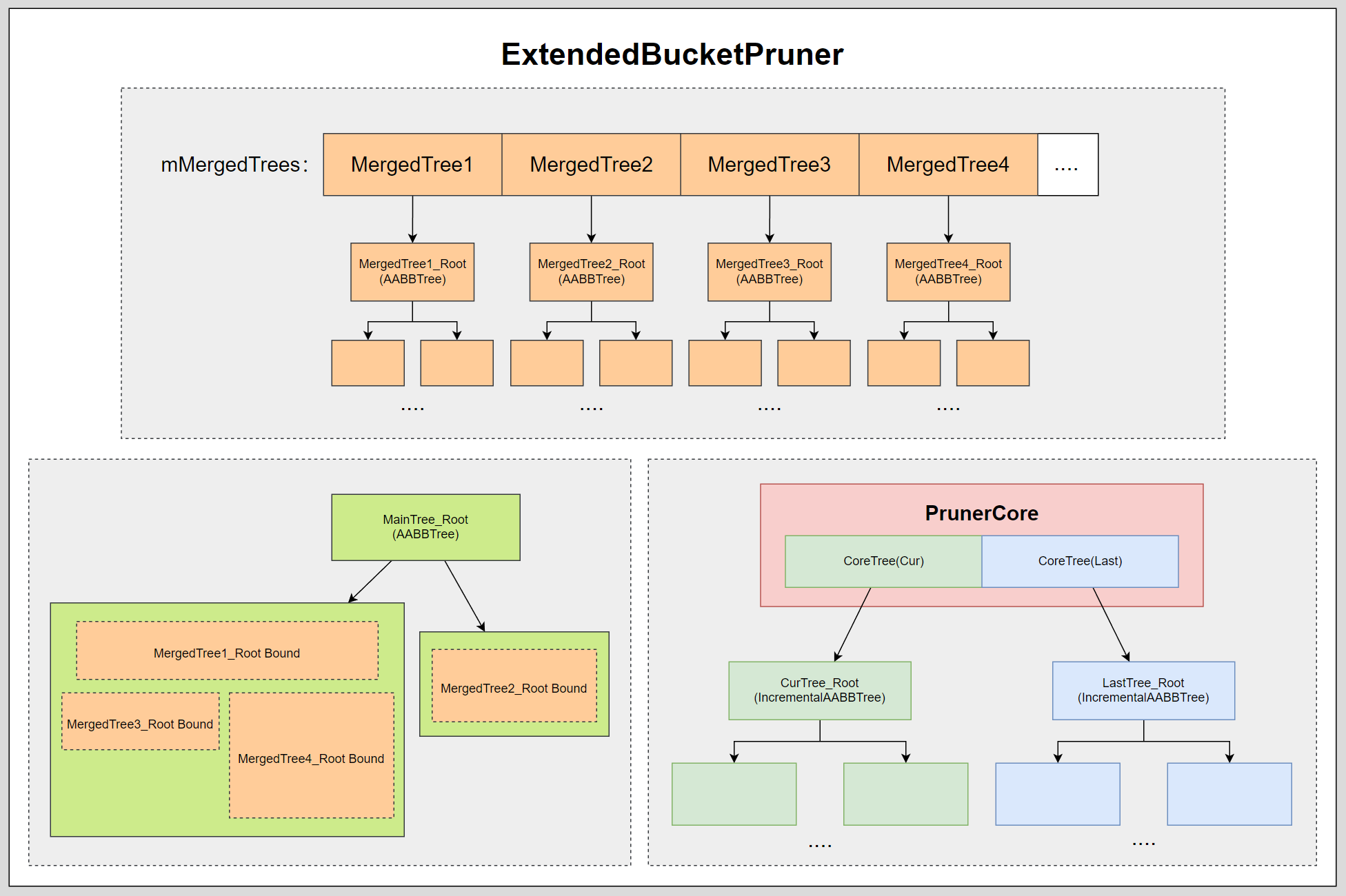
如果新增的是整棵树,那么把该树添加到 MergedTree 并重新构建 MainTree。如果新增的是某个节点,那么就添加到 PrunerCore 中的 IncrementAABBTree 内。
# NewTreeFixup

NewTreeFixup 用来记录删除包围盒操作所影响的两个包围盒下标。至于为什么是两个,之前在 PruningPool 中也有简单的介绍,为了保证数组连续,会用末尾的数据填充到删除位置,因此删除操作实际上是一次替换,把最后一个位置的数据替换到删除位置,所以这里需要记录两个下标。具体删除细节可以回顾一下 PruningPool.removeObject。
# AABBPruner 的增删改
AABBPruner 增删改操作本质是都是对 AABBTree && IncrementAABBTree 的封装,具体实现细节其实已经在 AABBTree 和 IncrementAABBTree 做了详细介绍,这里主要是基于更上一层的规则进行梳理:
# 不考虑交替帧渲染的情况
为了方便讨论,先介绍一下不做交替帧渲染情况下 AABBPruner 如何增删改的,以下讨论均建立在 mIncrementalRebuild = true 的情况下。
下图是简化后的 AABBPruner 结构图:
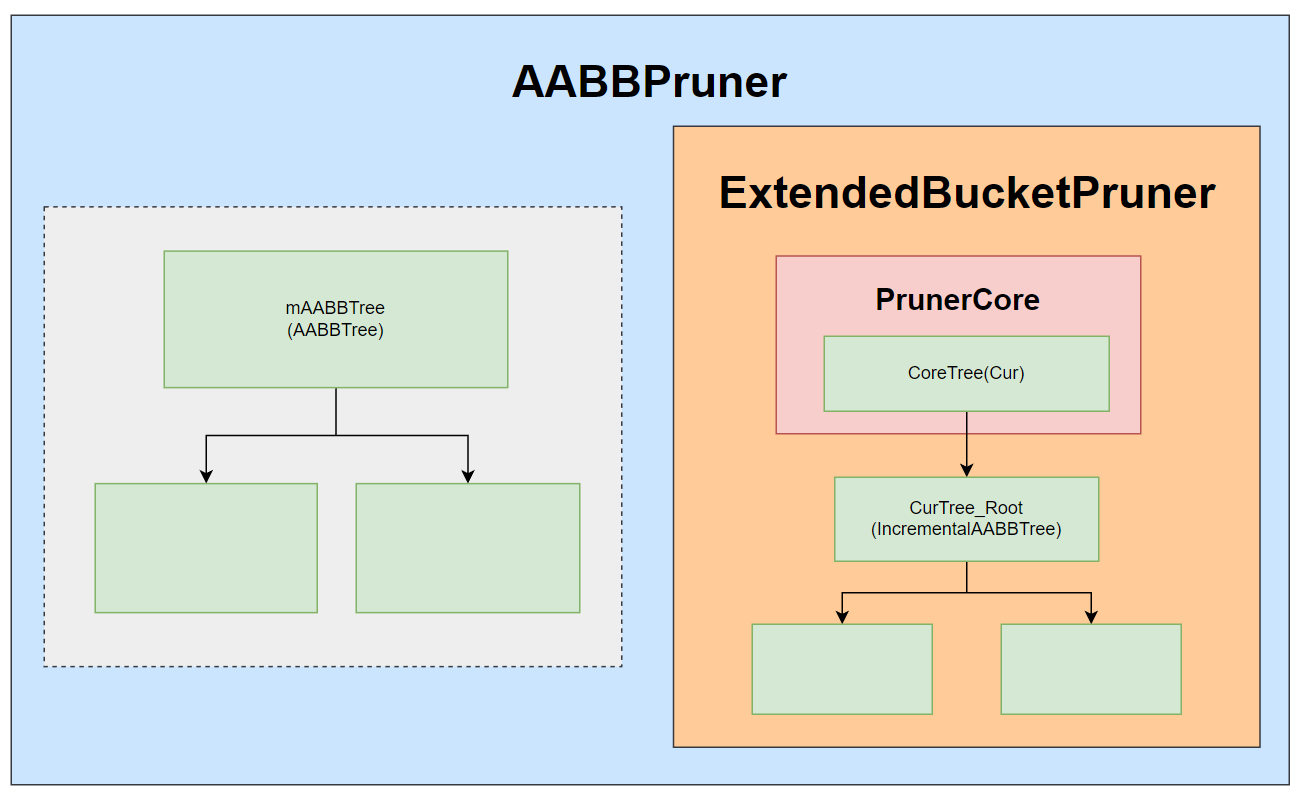
实际用到的结构只有 mAABBTree (AABBTree) && ExtendedBucketPruner.PrunerCore.CurTree (IncrementAABBTree) 两个。
# 新增操作
由于 mAABBTree 只支持树级别的新增,并不支持节点的新增操作,因此新增逻辑的支持交给了 ExtendedBucketPruner.PrunerCore.CurTree。具体实现细节可以回顾 AABBTree 篇的 IncrementAABBTree 部分。
# 删除操作
删除操作其实分为两种情况:
- 删除在 mAABBTree 中的节点。
- 删除在 ExtendedBucketPruner.PrunerCore.CurTree 中的节点。
辨别方法也比较简单,AABBPruner 里面的 mTreeMap 维护了 mAABBTree 包含的全部 bound 映射,如果该映射关系内没有找到被删除的包围盒,那就一定在 ExtendedBucketPruner.PrunerCore.CurTree 里,删除细节也可以参考 AABBTree && IncrementAABBTree。
# 更新操作
更新和删除比较相似,这里也不多介绍。
# 交替帧渲染的情况
引入交替帧渲染后,情况就变得复杂起来,再介绍增删改之前,先介绍一下 AABBPruner 内的 buildStep 和 commit 的构建流程。
# 支持分布构建 buildStep
最早提到分布构建还是在 AABBTree 的 progressiveBuild 中,这里对 AABBTree 的分布构建做了一定程度的扩展,先来看看分布构建的流程:
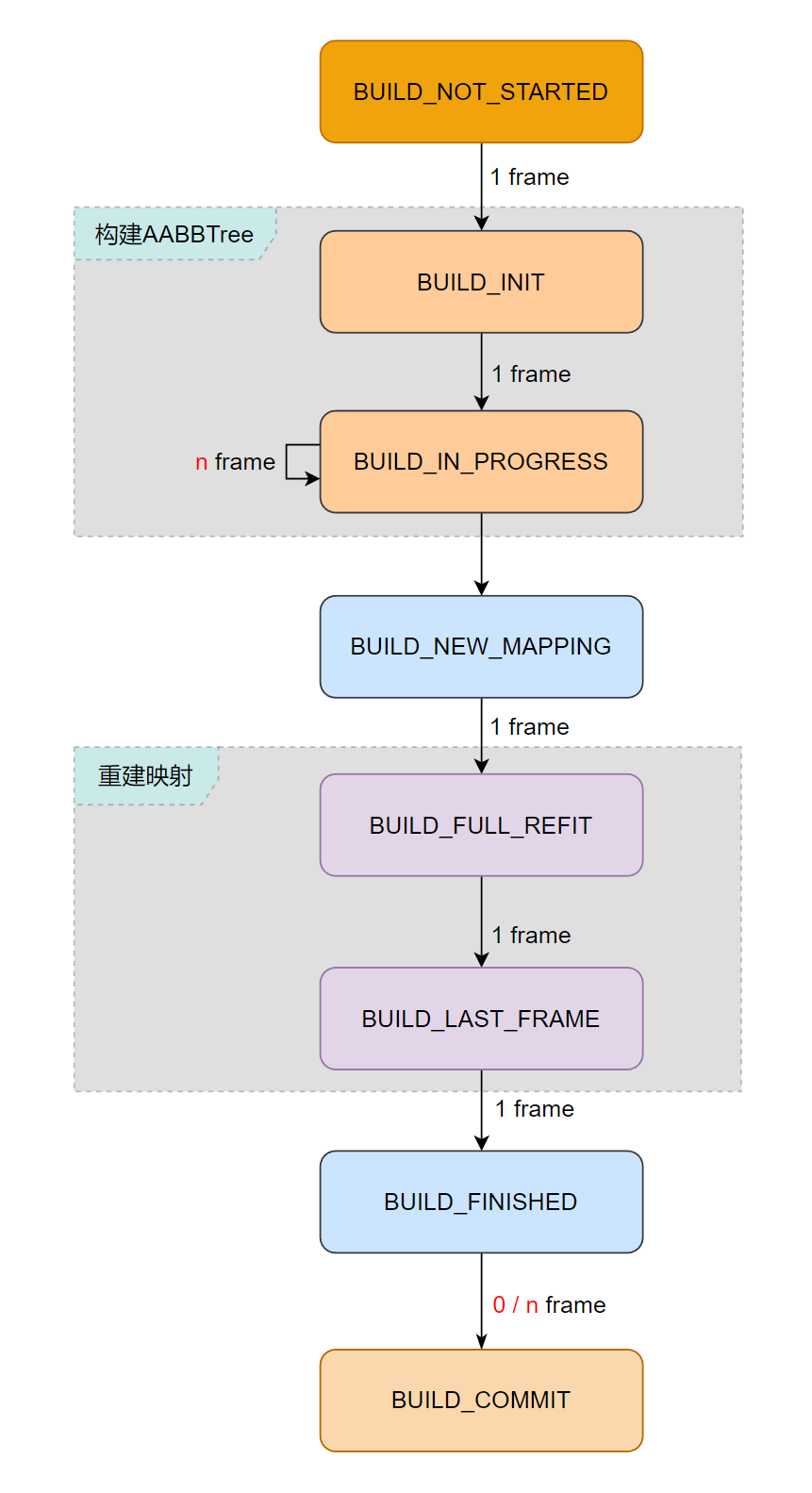
- BUILD_NOT_STARTED:表示还没有构建的状态,也是 AABBPruner 的初始状态。
- BUILD_INIT:该状态下,会对 mPool.mWorldBoxes 做一个深拷贝,并记录在 mCachedBoxes 中,作为新树构建的源数据。
- BUILD_IN_PROGRESS:拿到源数据之后,就可以开始构建 mNewTree。AABBPruner 会通过一种启发式算法控制构建次数实现平滑。
- BUILD_NEW_MAPPING:无操作。
- BUILD_FULL_REFIT:构建完成,需要重新生成一次 mapping 关系,并记录在 mNewTreeMap。
- BUILD_LAST_FRAME:有了映射关系,这里会再计算并更新一次树节点的包围盒信息 fullRefit。
- BUILD_FINISHED:无操作。
- BUILD_COMMIT:这并不是一个状态,而是 commit 函数,放在这里主要是便于理解。commit 目的是能够让构建结果应用在 mAABBTree 中,类比交替帧渲染里渲染好了,需要执行交替步骤。
# 启发式的平滑算法
如何有效的评估构建耗时并且尽可能的平滑结果,AABBPruner 定义了一个预估次数 mRebuildRateHint,默认情况下是 100 frame,可以支持动态设置。
mRebuildRateHint 仅仅是一个预估值,这也意味着很可能并非实际结果,为了趋近于预估又引入了三个系数:mNbCalls、mTotalWorkUnits、mAdaptiveRebuildTerm。
- mNbCalls 记录的是本次构建实际消耗了多少 frame。
- mAdaptiveRebuildTerm 是一个调节参数,如果实际结果超过预期说明估少了,那么就 + 1 反之 - 1,如果和上次构建的工作单元差距过大,这个值会被重置。
- mTotalWorkUnits 总工作单元可以理解为一次完整构建,需要访问的包围盒次数,例如 8 个包围盒最终构建出如下的树形结构,那么总工作单元就是 ,这里并不计算叶节点层。当然计算实际总工作单元没有任何意义,我们需要的是预估值,这里的计算公式大概长这样:
- leafnb:叶节数量。
- depth:预估的树深度, 。这里假设这棵树是完全平衡的。
- mTotalWorkUnits: 。实际会比这个复杂一些,还会参考上一次构建时的估计结果。
# 为什么需要构建新树🤔
回到之前的「不交替渲染」,它也可以很好的工作,支持增删改查。为什么还要大费周章构建新的 AABBTree 呢?
- 极端情况下,mAABBTree 的节点会全部被删除,AABBPruner 会退化成 IncrementAABBTree,在 AABBTree 章节也介绍了 IncrementAABBTree 远比 ABBTree 更加的占用内存,而且低效,唯一的优势只有支持新增节点。
- 删除的 mAABBTree 节点不会被回收,因此会造成内存碎片。
- IncrementAABBTree 作为新增节点的暂存器,每次构建新树的时候会把 IncrementAABBTree 的节点也纳入构建,在构建完成后可以清空 IncrementAABBTree,因此频繁构建新树的情况下,IncrementAABBTree 内的节点会非常少。
- 构建操作虽然较为耗时,但只要能够做到很好的平滑,实际上可以减轻对于性能的开销。
# 如何保证构建新树时查询功能依旧可用
可以看到构建一个新树大概需要 100 frame,这段时间里如何保证场景查询还是可靠的呢?回到之前的不交替渲染,实际上已经能够支持在运行过程中增删改了。AABBPruner 为了保证可用性的情况下为很多数据都做了副本,例如 mAABBTree && mNewTree、mTreeMap && mNewTreeMap、mPool.mWorldBoxes && mCachedBoxes,就是为了保证构建和查询完全分离。因此在支持交替渲染情况下的 AABBPruner 可能就长这样:
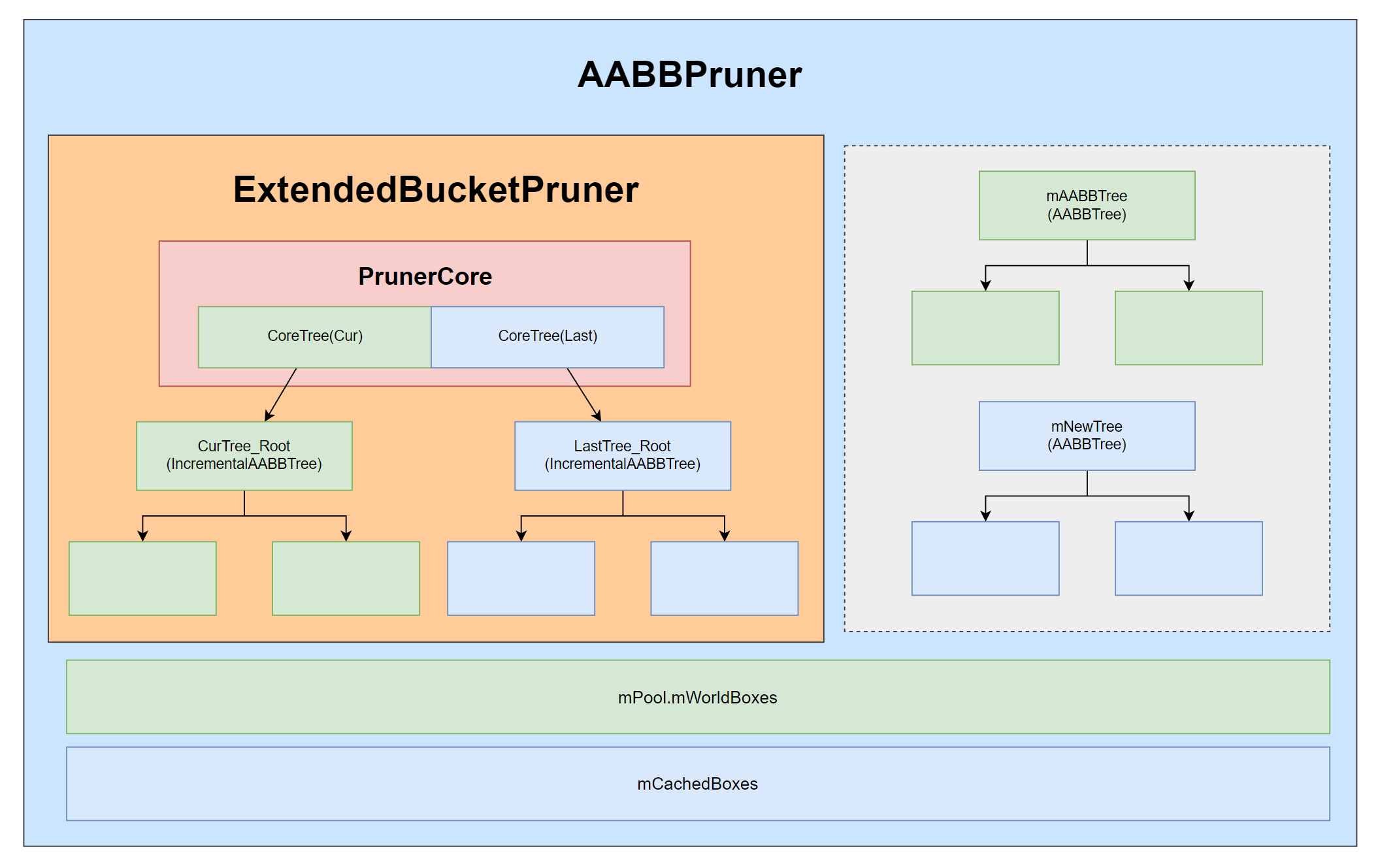
mAABBTree + CoreTree (Last) + CoreTree (Cur) 保证了增删改查的实时性,mNewTree 构建数据源于 mAABBTree + CoreTree (Last)。因此在每次构建完成后,mAABBTree 的内容会被替换成 mNewTree,相应的 CoreTree (Last) 将会失效,而 CoreTree (Cur) 将会在下一次 mNewTree 构建开始时切换为 CoreTree (Last)。
# 如何保证新树的一致性
思考这样一个问题,假设物体的包围盒一直更新,mNewTree 就用永远都是旧的。最直接的一个例子:BUILD_INIT 状态下会拷贝 mPool.mWorldBoxes 结果构建 mNewTree,这个构建可能持续大概 100 frame,中途新的变更例如删除、添加和更新并不会影响 mNewTree,所以它还是停留在 100 frame 之前的状态,如果这时候进行替换,将会丢失这 100 frame 的全部操作。这显然是无法接受的。
AABBPruner 做法是保存这 100 frame 的全部操作,在新树构建完成时进行应用:
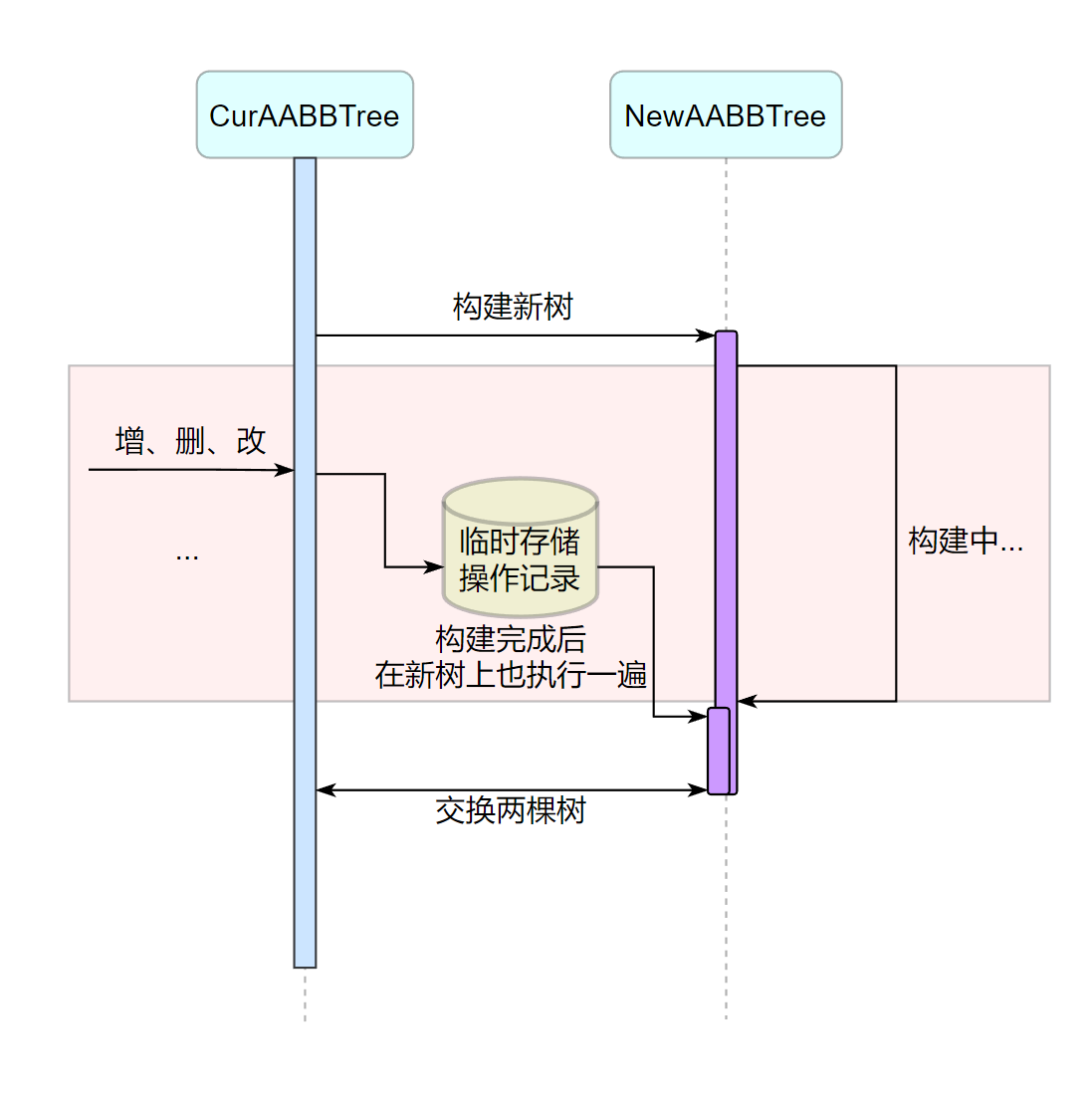
# 新增操作的存储
前面提到 IncrementAABBTree 会在新树构建完成后被清理,并且节点新增都会存储在 IncrementAABBTree 内。如果把 IncrementAABBTree 作为存储新增操作的容器,则需要至少两个 IncrementAABBTree。一个是旧的 IncrementAABBTree,数据是构建开始时刻的;另一个是构建过程中新增的,也就是本次构建开始到下次构建开始的所有新增内容,旧的会在本次构建完成后清空,新的则会保留到下次构建结束。这也是为什么会有 CoreTree (Cur) 和 CoreTree (Last)。
# 删除操作的存储
删除操作很难对两棵树做差进行求解,最简单的办法就是存储一个操作记录,类比数据库迁移和数据恢复。AABBPruner 会把删除记录存储在 mNewTreeFixups,然后在新树构建完成后把这些删除操作再执行一次,用于保证和当前数据的一致。
# 更新操作的存储
更新其实类似,会记录需要更新的包围盒下标数组 mToRefit。有一点需要注意,由于 mNewTree 构建流程中本身就会执行一次全量更新 fullRefit。因此可以利用这个更新提前先把一部分的修改应用在 mNewTree 中,因此更新其实分成了两部分:
- 在 BUILD_LAST_FRAME 下的更新:这里的更新稍微取巧了一下,没有把更新记录在 mToRefit 内,而是直接用的 mPool.mWorldBoxes 作为数据源更新的 mNewTree,好处是可以省去 mToRefit 记录的差量,直接从差值更新转为全量更新了,但是这样实际上会有一个问题。试想一下,一棵用 mCachedBoxes 构建的新树,再用 mPool.mWorldBoxes 去更新,中间差了大约 100 frame,这 100 frame 内的新增操作由于是记录在 IncrementAABBTree 里的,所以可以忽略;但删除却不行,而且删除操作会影响 bound 到 TreeNode 的映射,会导致更新的时候错乱。因此,为了解决删除时映射不一致的情况,这里会提前处理一次 mNewTreeFixups 内的删除记录,然后再做更新。
- 在 COMMIT 下的更新:commit 更新就不需要全量更新了,因此可以通过差值更新实现,这时候 mToRefit 才算是真真意义上的派上用场。
# AABBPruner 的查询
最后让我们再看看 AABBPruner 的查询。查询接口主要有三个 raycast、sweep 和 overlap,但这里并不打算过分展开,我们仅探讨查询时需要考虑那些数据。
首先,我们已经有了足够实时的 mAABBTree,删改操作可以立马在上面得到体现;以及支持新增节点的 PrunerCore。 PrunerCore 的两棵 IncrementAABBTree 存储了不同时间段的新增节点,但即便如此它们两个都是有效的,因此所有的查询都必须查找 PrunerCore 内的两棵树以及 mAABBTree。
// 先查 mAABBTree | |
if(mAABBTree) | |
again = AABBTreeRaycast<false, AABBTree, AABBTreeRuntimeNode>()(mPool.getObjects(), mPool.getCurrentWorldBoxes(), *mAABBTree, origin, unitDir, inOutDistance, PxVec3(0.0f), pcb); | |
// 再查 mBucketPruner | |
if(again && mIncrementalRebuild && mBucketPruner.getNbObjects()) | |
again = mBucketPruner.raycast(origin, unitDir, inOutDistance, pcb); |
PxAgain ExtendedBucketPruner::raycast(const PxVec3& origin, const PxVec3& unitDir, PxReal& inOutDistance, PrunerCallback& prunerCallback) const | |
{ | |
PxAgain again = true; | |
// 先查 mBucketPruner.mPrunerCore | |
if (mPrunerCore.getNbObjects()) | |
again = mPrunerCore.raycast(origin, unitDir, inOutDistance, prunerCallback); | |
// 在查 mBucketPruner.mMergedTrees | |
if (again && mExtendedBucketPrunerMap.size()) | |
{ | |
const PxVec3 extent(0.0f); | |
// main tree callback | |
MainTreeRaycastPrunerCallback<false> pcb(origin, unitDir, extent, prunerCallback, mPruningPool); | |
// traverse the main tree | |
again = AABBTreeRaycast<false, AABBTree, AABBTreeRuntimeNode>()(reinterpret_cast<const PrunerPayload*>(mMergedTrees), mBounds, *mMainTree, origin, unitDir, inOutDistance, extent, pcb); | |
} | |
return again; | |
} |
可以看到 mBucketPruner.mPrunerCore 两棵树都需要进行查询:
for(PxU32 i = 0; i < NUM_TREES; i++) | |
{ | |
const CoreTree& tree = mAABBTree[i]; | |
if(tree.tree && tree.tree->getNodes() && again) | |
{ | |
again = AABBTreeRaycast<false, IncrementalAABBTree, IncrementalAABBTreeNode>()(mPool->getObjects(), mPool->getCurrentWorldBoxes(), *tree.tree, origin, unitDir, inOutDistance, PxVec3(0.0f), pcb); | |
} | |
} |
其实还有一个结构之前一直忽略了,那就是 mBucketPruner.mMergedTrees,不聊它是因为真的不是很重要 (bushi。
其实是应用场景比较少,不过还是简单介绍一下吧,mBucketPruner.mMergedTrees 的查询会先用 mMainTree 定位根节点,再通过对应的 mergedTree 查询。
另外和 CoreTree 类似,在 mNewTree 构建的时候,也会把 mMergedTrees 加入构建,并在构建完成后清理 mMergedTrees。
# 总结
本章节介绍了 AABBPruner 的实现细节,简单介绍了 AABBTreeUpdateMap,顺带填了一波 AABBTree && IncrementAABBTree 中 AABBTreeBuildParams 由来的坑,并梳理了一下 AABBPruner 是如何协调 AABBTree && IncrementAABBTree,通过分布构建的形式进行削峰。另外上述的讨论都是基于 mIncrementalRebuild=true 情况下,有兴趣的小伙伴可以自己思考一下关闭 mIncrementalRebuild 情况下,AABBPruner 又是如何呢。